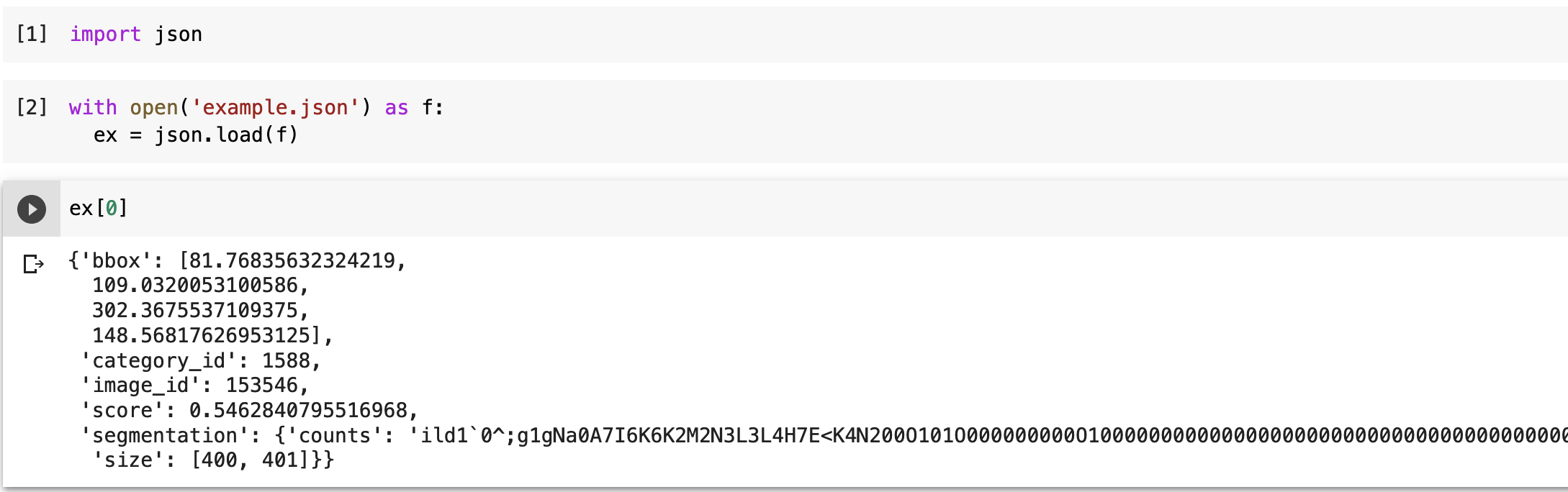
Hi @alieksandr_komin,
The annotations present in the validation & training dataset are different from what is expected as a submission.
Useful resources:
COCO: Format for the results
[{
"image_id": int, "category_id": int, "bbox": [x,y,width,height], "score": float,
}]
Link to learn more: https://cocodataset.org/#format-results
COCO: Format for the datasets
{
"info": info, "images": [image], "annotations": [annotation], "licenses": [license],
}
info{
"year": int, "version": str, "description": str, "contributor": str, "url": str, "date_created": datetime,
}
image{
"id": int, "width": int, "height": int, "file_name": str, "license": int, "flickr_url": str, "coco_url": str, "date_captured": datetime,
}
license{
"id": int, "name": str, "url": str,
}
annotation{
"id": int, "image_id": int, "category_id": int, "segmentation": RLE or [polygon], "area": float, "bbox": [x,y,width,height], "iscrowd": 0 or 1,
}
categories[{
"id": int, "name": str, "supercategory": str,
}]
Link to learn more: https://cocodataset.org/#format-data
Due to this, your submissions which are in dataset format are failing. You can translate them to the results format for successful submissions.
You can also download an example predictions file to learn more as well. 
 Other common pitfalls to look out for:
Other common pitfalls to look out for:
-
image_id, category_id, etc are int and not string.
- while generating your predictions file please make sure that you are not writing
numpy objects, and convert them to int / float respectively.