First of all, many thanks to the organizers for their hard work(the AICrowd platform& the Shopping Queries Dataset[1]).
And I learned a lot from the selfless sharing of the contestants in the discussion board.
Below is my solution:
+-----------+---------------------------+-------------------+-----------+
| SubTask | Methods | Metric | Ranking |
+-----------+---------------------------+-------------------+-----------+
| task1 | ensemble 6 large models | ndcg=0.9025 | 5th |
+-----------+---------------------------+-------------------+-----------+
| task2 | only 1 large model | micro f1=0.8194 | 7th |
+-----------+---------------------------+-------------------+-----------+
| task3 | only 1 large model | micro f1=0.8686 | 8th |
+-----------+---------------------------+-------------------+-----------+
It seems to me that this competition mainly contains two challenges:
Q1.How to improve the search quality of those unseen queries?
A1: we need more general encoded representations.
Q2.There is very rich text information on the product side, how to fully characterize it ?
A2: As the bert-like model’s “max_lenth paramter” increases, the training time increases more rapidly.
We need an extra semantic unit to cover all the text infomation.
A1 Solution:
Inspired by some multi-task pre-training work[2]
In pre-training stage, we adopt mlm task, classification task and contrastive learning task to achieve considerably performance.

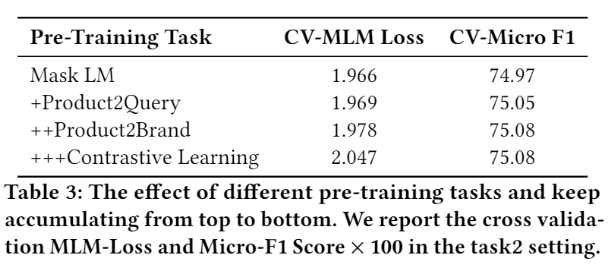
A2 Solution
Inspired by some related work[3,4]
In fine-tuning stage, we use confident learning, exponential moving average method (EMA), adversarial training (FGM) and regularized dropout strategy (R-Drop) to improve the model’s generalization and robustness.
Moreover, we use a multi-granular semantic unit to discover the queries and products textual metadata for enhancing the representation of the model.

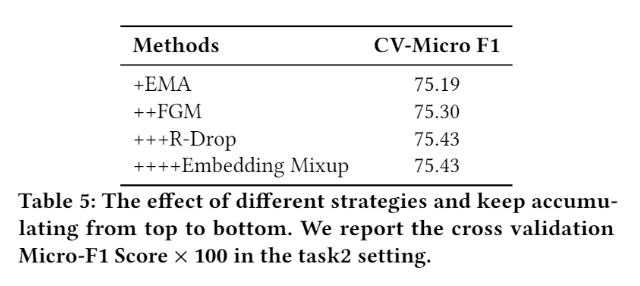
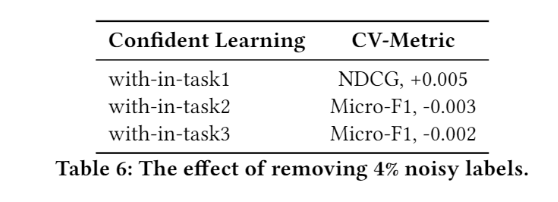
In this work, we use data augmentation, multi-task pre-training and several fine-tuning methods to imporve our model’s generalization and robustness.
We release the source code at GitHub - cuixuage/KDDCup2022-ESCI
Thanks All~ ![]()
Looking forward to more sharing and papers
[1] Shopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search
[2] Multi-Task Deep Neural Networks for Natural Language Understanding
[3] Embedding-based Product Retrieval in Taobao Search
[4] Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook