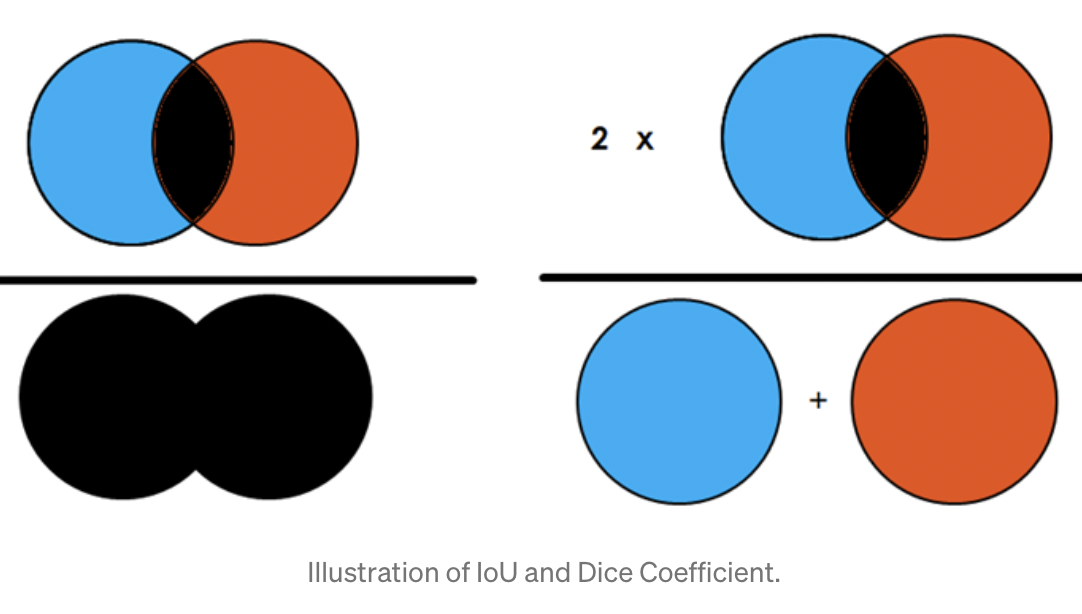
Hello, is the calculation for dice coefficient incorrent in local_evluation.py? I don’t think it is just 2 times the mean iou, since the iou has the union of predicted and target areas in the denominator, while the dice coefficient sums up the area of predicted and target classes (without subtracting the intersection).
Here’s a more visual representation from a medium blog. Iou on the left, and Dice coefficient on the right.
Hey everyone! I’m new to this website and wanted to give some feedback on the dataset for semantic segmentation, but it looks like I posted it in the wrong category / it’s not showing up in the forum in the dedicated feed for this contest.
Here is the post:
Hi! I downloaded the datasets, but it has only 1786 input images (and 1786/5 = 357.2, therefore not 5 frames per flight here) while the overview page says “5 frames per flight at different AGLs”.
I suppose the difference in number of images is because the “secret” test set has the rest of the images. BTW, I would suggest a limit to the number of submissions, otherwise the test dataset will “leak” into the model.
The dataset contains 422 flights, 2056 total frames (5 frames per flight at different AGLs), Full semantic segmentation annotations of all frames and depth estimations. The dataset has been split into training and (public) test datasets. While the challenge will be scored using a private test dataset, we considered it useful to have this split to allow teams to share their results even after the challenge ends.
Of the total frames available, a subset if used for the (public) test set that you are currently being scored on. There will be an additional (private) test set that the final leaderboards will be based on. And submissions are currently limited to 5 submissions / day.
Hi! 5 frames per flight is an average, as you noticed there is slightly less. The “missing” frames are not used in any set, the “secret” test set will contain entirely new scenes.
@gaurav_singhal The leaderboard links are fixed; thanks for flagging them. The leaderboard on the challenge overview page says, “This leaderboard is made available only to show the aggregated performance of teams across both tasks and has no associated prizes. The prizes are awarded based on the individual task leaderboards.”
Hi, I am having a lot of trouble navigating through the logs for errors.
I am wondering why a “failed” submission is actually counted as a submission (a “failed” submission is not counted as a submission on a competitor platform starting with a K) …
I assume you mean Kaggle. As far as I know, they do not provide logs, and failed submissions are counted on their platform.
We have a feature to count failed submissions, but that is set based on the preferences of the organizer, we’ll discuss will the AWS team if they want to give a separate quota for failed submissions.
Can you please let us know the submission link where you are facing the issues going through the logs.
Thanks @dipam for your answer.
I have been a avid participant in Kaggle and the “failed” submissions are not counted towards the 5 submissions a day which would be kind in this setup since we need to submit a running model to a live server (and not a simple notebook).
I have to say that the logs are quite enigmatic and confusing with error message that aren’t clear and it took me many tentative to figure something out. I haven’t been able to install tensorflow 2.11. (2.7 works: why? no idea) but I have something that works that I didn’t expect at all.
Thank you for the feedback. We’ll certainly try to improve the logs we provide. If you’re still facing specific issues please do share a submission link and I’ll do my best to help resolve it.
I would like to point out that our build logs are provided as is, without any filtering, so if there is any install time error, that should be available directly, and the quality of those logs would entirely depend on the library provider.
As for Kaggle and failed submissions, admittedly I haven’t taken part there in a while. However, I’m fairly certain failed submissions got counted for code based competitions (refer here) with a hidden test set, which is the case for the SUADD’23 Challenge.
@dipam You are correct: for code based, fails counts toward daily submissions limit.
I have another question: is there a final leaderboard calculated at the end of the competition based on a separate set of images from the current leaderboard ?
Yes, the final winners will be selected based on a different test set, to avoid overfitting the leaderboard. This is mentioned in the rules. Thank you for pointing this out, evidently we should make it clearer in the Challenge Overview.
Do the baseline model scripts work anymore? I’m trying to apply the patch ai blitz has provided, but it is failing - presumably because the mmsegmentation repo has been updated, and the patch is now out of date.
I’d appreciate it if someone could help me get the baseline submission done, and correct me if I’m misunderstanding something - specifically, can the current baseline repo still be used in its current state?