Hi all,
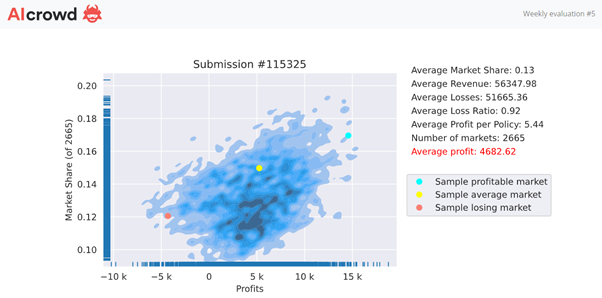
Last week, I shared my Weekly Feedback chart and associated thought process.. Looking at the distribution of my market and the market share %… I came to the realization that I had to go back to the drawing board.

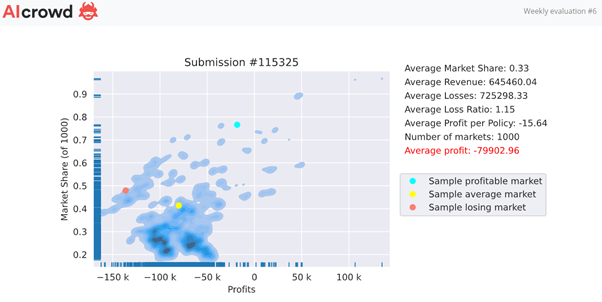
A new week, a new model, a new feedback…
This time ranked 8 on the profit leaderboard with a moderate $6420 avg profit.
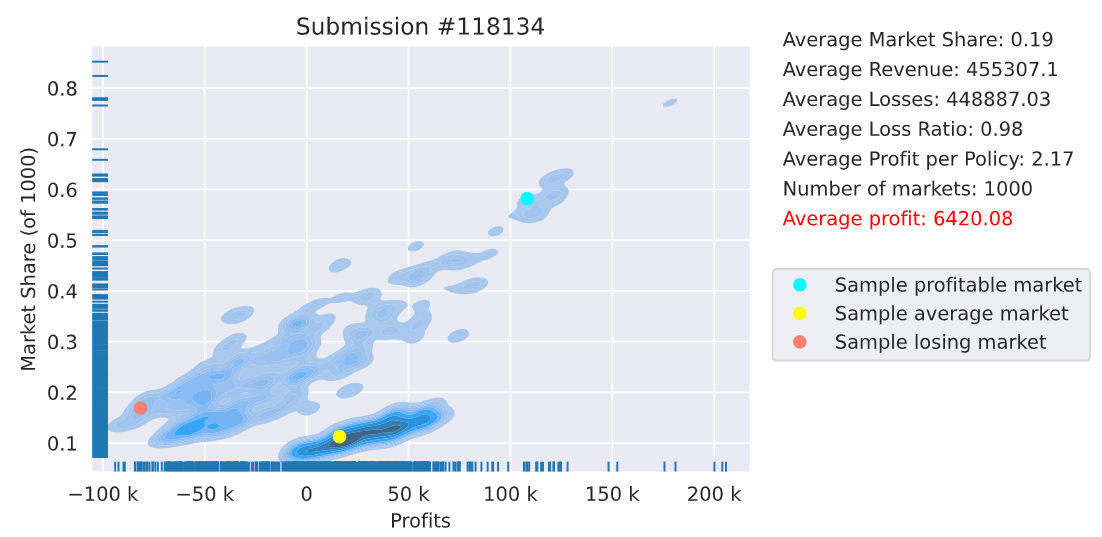
@alfarzan, this time, both set of metrics are in the same direction. 
Thoughts on my results at initial glance:
- The bottom cloud, being the bulk, low market share, “okay” profit.
- The actual shape is interesting, going upwards from left to right…
- … the more market share I have, the more profit I make (!?)
- Looks like I will try to hunt for more market share.
Thoughts on the leaderboard:
- top insurers are generating fatty profit, congrats.
- and bottom are loosing,… a lot! taking the hits for the team.
This is when I read back the evaluation and I’m looking for clarification.
To make sure that results are stable, we keep putting you in markets until your leaderboard rank no longer changes from market to market.
^That I understand.
But then further down it details even more the metric.
Is the realistic competitive profit computed in the weekly leaderboards? Or is that only for the end ?
Compute realistic
competitive profit. In a realistic market models that don’t perform well don’t exist (i.e. go bankrupt). So to compute the realisticcompetitive profit, we place your model in a market of size 10 with 9 other models picked from the top 10% of the the ranking obtained in step 1.
I’m asking because I have a feeling, from my leftish top cloud, that those markets (the red dot  ) , was when I got to compete against top insurers such as @simon_coulombe.
) , was when I got to compete against top insurers such as @simon_coulombe. 
If “realistic profit” isn’t computed weekly, then I think I just got a glimpse of what’s to come next in March…
 dreaded adverse selection
dreaded adverse selection 
EDIT: just noticed that the number of markets is only 1,000 (vs 4k+ last week). Is this normal? Are players subject to roughly the same quantity of market evaluations? I can understand slight variance to account for convergence, but this is a significant difference between two weeks.
My guess is that you reduced market quantity to offset the computation required for the extra rows?
 mainly because it is showing the development of your strategy
mainly because it is showing the development of your strategy  without revealing much.
without revealing much. Sometimes they are, but sometimes they are just top of round 1 because they kept playing against less sophisticated models in round 1. In that case, they lose their positions
Sometimes they are, but sometimes they are just top of round 1 because they kept playing against less sophisticated models in round 1. In that case, they lose their positions 

 !
!




 not with me!
not with me!