Oh wow where to start 
A lot of really good discussion is happening here 
I’ll just chip in with a few thought and to address some questions raised above.
Some clarifying facts 
- Leadeboards do not contain any training policies (@sandrodjay1)
- All feedback, and leaderboards are based on round 2 of the markets (@simon_coulombe)
- In round 2 everybody plays against the top 10% of round 1 (including the top 10% themselves) (@simon_coulombe)
Ok now that we got that out of the way, the interesting stuff 
Effect of leaderboard size 
@sandrodjay1 mentions that with a larger portfolio within your grasp then these large swings should be diminished. This is only partly true. There is a positive effect because of:
-
Large claim buffer. A larger portfolio protects you against the impact of large claims.
-
Representative sample. A larger portfolio is more likely to closely resemble the final dataset, and hence represent your claim estimation overall.
These two reasons are why we bolstered the dataset size and introduced reinusrance (i.e. capped claims).
But how effective is the size? Actually let’s see the underlying analysis behind this.
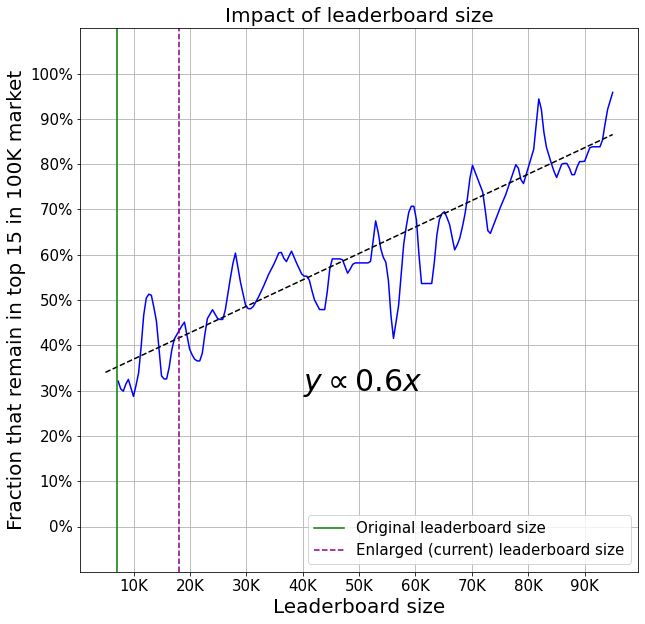
Here is a plot where on the X-axis you can see larger and larger samples of a set of 100K policies. On the Y-axis you can see the fraction of models that remain in the top 15 models when the size is increased to 100K.
So you can see, roughly speaking, that for every 10K rows added, you’re getting 6% more in models that remain in the top 15. (For top 10 the growth is faster but has a lower starting point, the reverse is true for the top 20). Right now that number is close to 40%.
Note: remember that these are the same models engaged in markets with different sized leaderboards. If we also use different models the Y-axis values are slightly lower.
Why didn’t we just give you a huge portfolio?
There are 2 key reasons for this:
-
Realism. We didn’t want you repeatedly price the same policies and get feedback about them.
-
Data limitations. Because we don’t want to allow multiple pricing of the same portfolio we have to make the data go for 9 weeks or more. 20K was our limit

We had to strike a balance, and given that in real markets any year you may see some swings, we decided that this is a good trade off. Of course models that have good claim estimation and a great unique strategy will come out on top much more often than others, while some may only have their “15 minutes of fame”.
So you can see that the swings exist and may be large for individuals, but for the leaderboard, they are not that bad. But if size is not the whole story, what else?
Fierce competition + no cumulative leaderboard = large swings 
In the real world, we don’t see these large swings for many reasons. Some of the more obvious of these are:
-
Complex customer behaviour. Markets are not cheapest wins
-
Dataset advantage. Incumbents have large dataset advantages in their respective niches
-
Leaderboard frequency. Frequency of real-world “leaderboards” is closer to yearly
These 3 points alone make the real-world markets a little more consistent year by year (my intuition is that the importance is (1) >= (2) > (3)). There are many other factors, such as very strict regulation, that also play important market stabilising roles.
In this challenge, leaderboards are faster  ♂, customers are extremely disloyal
♂, customers are extremely disloyal  , and there is no incumbent dataset advantage (after all we want everyone to have the same chance!).
, and there is no incumbent dataset advantage (after all we want everyone to have the same chance!).
There is only claims modelling and pricing strategy, keeping all else the same.
So what can happen is that there can be large swings for some of the ranking positions when, due to small changes in pricing strategy or modelling, suddenly one model is constantly beating another.
Why did we go with such a setup?
-
Simplicity. We wanted to make sure that the setup is very easy to understand.
-
Accessibility. We didn’t want people joining in week 4 to be severely disadvantaged due to some missed dataset advantage.
-
Fun. We decided on the weekly profit leaderboard rather than something like monthly
With all this in place, it still looks like we do have some of the top market players already recognised, but as with any competition (especially this one), that can change towards the end 
But of course we’re still learning how to build a market in a realistic way! so keep the thoughts coming 
 )
) And don’t you think that 18k*market_share are indeed not enough policies to ensure a stable portfolio?
And don’t you think that 18k*market_share are indeed not enough policies to ensure a stable portfolio?