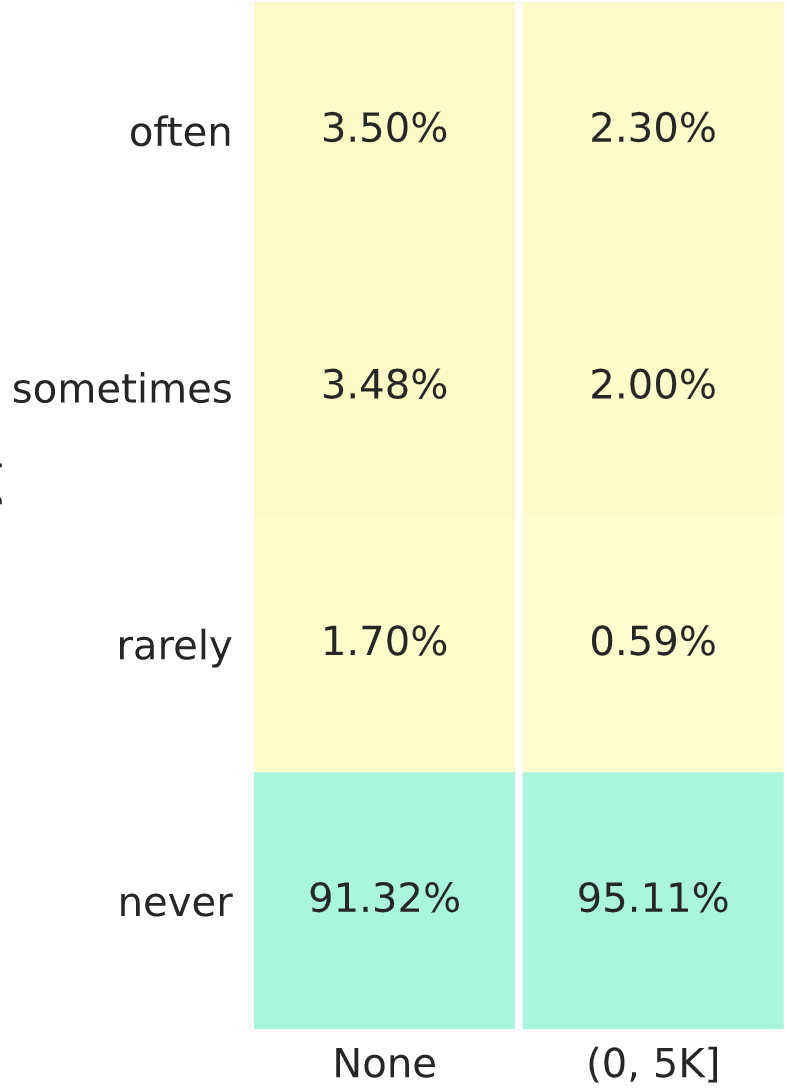
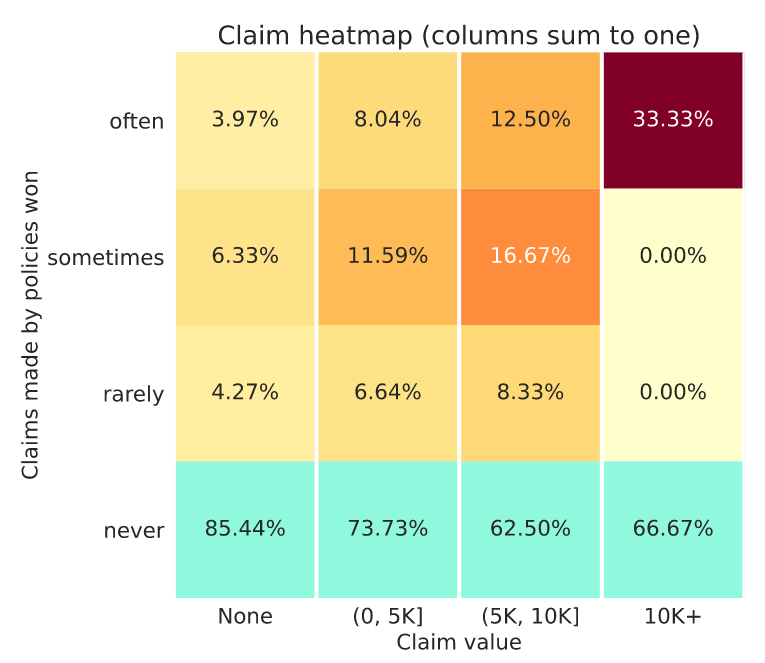
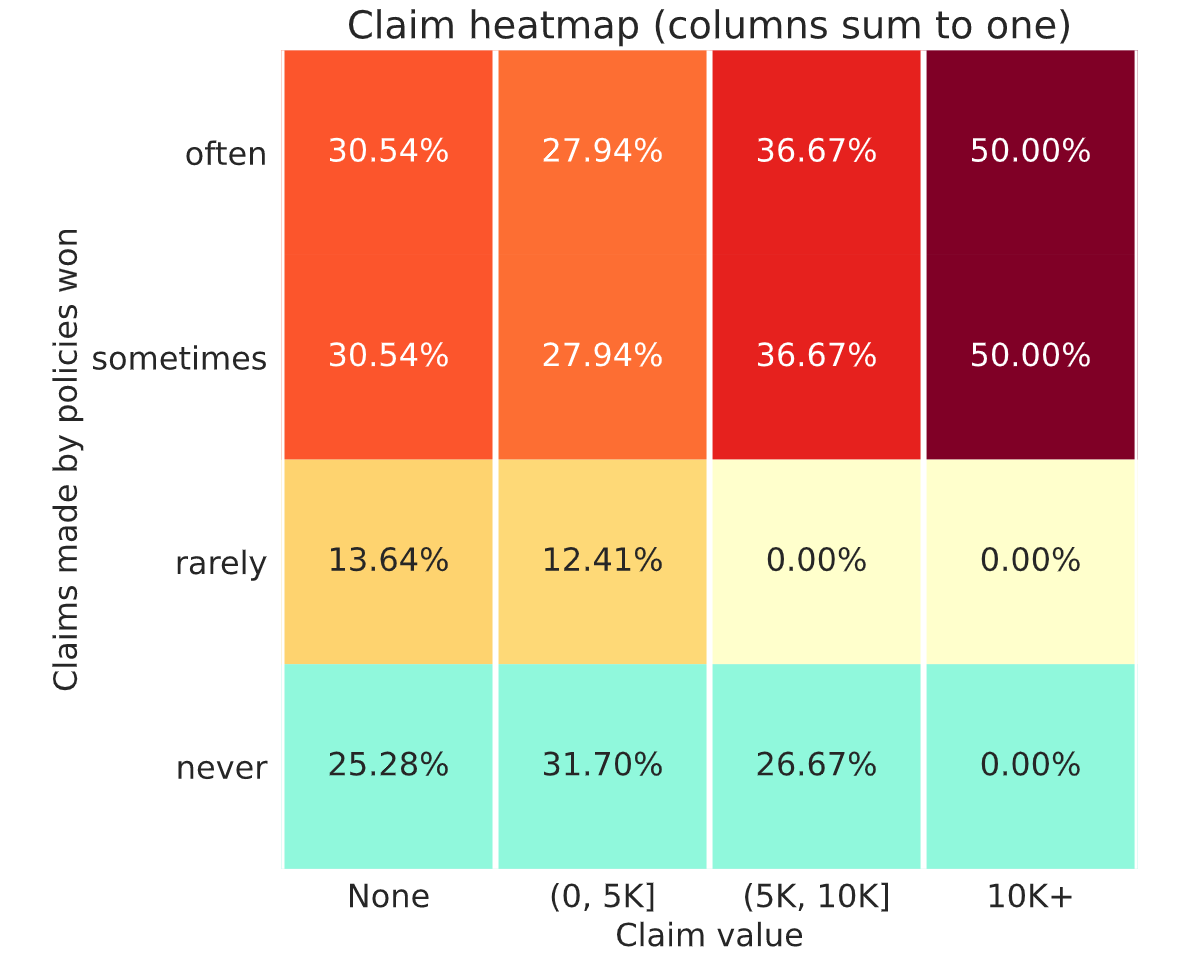
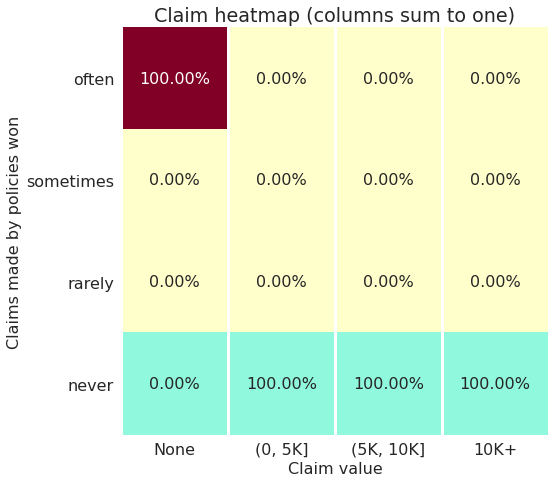
Just to confirm, each of the rows (excluding the “never” row) sum up to roughly the same number of policies as they are quantiles (the same as the rows on the tables below).
@guillaume_bs what is the confusion on that point? Is it something I can help clarify?
@lolatu2 actually the hope is that we’ll be able to provide the community with those insights a few weeks after the end of the competition during an online event anyone can join and contribute to! That’s not only to save you from having to read my thesis.
Thanks @alfarzan for confirming.
Here what puzzles me is that on all claims segments the “often” figures are much higher than the “rarely” ones. I don’t think these figures would be possible with the same number of policies in each row.
So these column normalised, meaning columns sum to 100%. So the heatmap is telling you about the wider market and your performance within it.
Toy example with 10K policies
Let’s take a toy example where there are a total of 10K policies in the whole dataset, and and we only have two columns, the None (A) and the (0, 5K] (B). Further let’s say they’re broken down such that.
Column A. 9K contracts Column B. 1K contracts
So what do the numbers in your heatmap mean?
How many policies does each row represent?
First let’s see how many policies you win with any frequency:
Column A. We know that 91.32% of these you never win. That means you win 8.68% of them in some situation. That’s 0.0868 x 9000 = 7821 policies. Split equally among the three rows that’s ~ 2600 policies per cell (excluding never)
Column B. Similarly for this column you will sometimes win 0.0489 x 1000 = 489 policies. That’s ~160 per cell
So what do the percentage numbers mean?
This heatmat is telling you how exposed you are to the entire market with the view on claim amounts.
Ok so what does it mean to say for the column A policies, you have 3.5% in the top cell? That means that the policies that you win often and don’t make a claim (~2600 policies), represent 3.5% of the entire set of policies that don’t make a claim in the market.
Similarly in column B, the top row with 2.3% means, that the policies you win often and have a claim less than 5K (~160 policies) represent 2.3% of all the policies that have made a claim in that range in the market.
I hope that makes it clearer (and that my maths is correct!)
Indeed it looks like the this week we have avoided larger claims. The two competitors at the very bottom of the leaderboard are giving us the weekly summary statistics.
Genuinely I have no idea what happened there. I was 4th last week, and then this abominable result this week, BUT I have not seen any leaderboard feedback for week 8 or 9 (ie, at all) so I have been fishing in the dark )
Anyone who can help explain it to me, i’d be happy
Ah your feedback is actually on the submission itself.
If you go to the leaderboard, click on “view” next to your leaderboard submission and then navigate to the “evaluation status” tab you will see the feedback
I think I may have joined this challenge a little late (week 8) to really get a handle on it, but I hope they do more like this. Adding this pricing aspect is way way more interesting than just claim model prediction
Thanks @alfarzan for your explanation, but I must say I am still a bit lost.
Taking your toy example with 10K claims, with a 10% frequency, and ignoring the last 2 columns which are very rare.
The policies won “often” represent 3.5% of the policies with no claims - around 3.5% x 9K = 315 - plus 2.3% of the policies with a small claim - around 2.3% x 1K = 23 - so the total here is around 338.
The policies won “rarely” represent 1.7% of the policies with no claims - around 1.7% x 9K = 153 - plus 0,59% of the policies with a small claim - around 0.6% x 1K = 6 - so the total there is around 159.
There are some approximations here, but overall, as the two values for “often” are larger than both values for “rarely” I don’t see any solution where the number of policies are equal… so I might be misinterpreting the heatmap somehow
If the number of policies is equally split among [often, sometimes and rarely] (the nominator), and the fractions are different, the denominator must be different.
As the (top 10) competitors are becoming niche and better, it is more likely for us to pick up underpriced policies, therefore apply a higher profit load protect us against it. All in all, if we have a super high profit load and not winning many policies, our profits will be close to 0 and enough to beat many other competitors. In other words, to beat the top and niche player, we need to be niche as well!
Ahh ok I see what you (and @davidlkl) originally meant now.
The answer is not going to be very satisfying I’m afraid: these are small measurement errors.
In reality when we have to construct the quantiles, it’s not always exactly equal and we have to allow the algorithm some leeway to make things approximately equal. When the market share is very low, when we are contructing these buckets, that error becomes relatively large. Hence the issue you observe.
I’m attaching another feedback with a average marketshare of ~0.05 so you can see that the numbers become closer when the buckets are constructed using more inputs.
Here assuming claim frequency of each category being 10% of the last.
I’m not sure what others think but I’d say that the ideal plot* could look something like this:
Of course you could say that if you price things properly you want to get some of the claims and still make money, but this is just one version of what a good plot could look like.
If I assume that’s your feedback from week 9 submission then I’d conclude that it’s not ideal.
In many ways it’s similar to my week 8 submission when I had a similar looking chart, a similar high market share and a low leaderboard position. The difference is my week 8 RMSE model was 500.1 ish and your week 9 is 499.46 ish.
Now you’d hope that a model with a much lower RMSE should be better at differentiating risk. If that was the case though you’d expect to write a smaller market share of the the policies with higher actual claims. Your chart though doesn’t show such behaviour. That may be because your good performance on the public RMSE leaderboard is not generalising to the unseen policies in the profit leaderboard. This could be a result of placing too much emphasis on RMSE leaderboard feedback and not enough on good local cross validation results. It can lead to unwittingly overfitting to the RMSE leaderboard at the expense of a good fit to unseen data.
Now I think I have a similar issue, ie a poor fitting model as my week 8 and week 9 charts are less that ideal… (I’d rather have a chart like @davidlkl but with greater market share). But the cause of my issue is that in seeking not to overfit too much I haven’t fit well enough relative to others.
Another point to investigate is your market share. A 30% market share, suggests your profit margin is set lower than competitors. In a pool of 10 people a 10% market share would be a a reasonable target to go for.
The only difference between my week 8 and week 9 submission was that I increased my rates by a fixed single digit percentage. I’ve learnt that I perhaps increased rates too much as my market share has fallen further than I’d like.
So for my final submission I’ll be refining my model and making a minor tweak to my profit margin. (And no doubt subsequently regretting doing so as I see my profit leaderboard position plummet!)



 (and that my maths is correct!)
(and that my maths is correct!)

 )
)