I have cloned and installed the latest flatland/baseline combos.
The torch training fails with an “impossible transition” exception after a few episodes:
Here is the output:
Training 3 Agents on (20,20).0.2 Episode 8190476 Average Score: -0.49924Dones: 0.00% Epsilon: 1.00 Action P
Training 3 Agents on (20,20).0.2 Episode 9184375 Average Score: -0.48167Dones: 3.70% Epsilon: 1.00 Action P
Training 3 Agents on (20,20).0.2 Episode 1090740 Average Score: -0.49193Dones: 3.33% Epsilon: 1.00 Action P
Training 3 Agents on (20,20).0.2 Episode 119 Average Score: -0.474 Dones: 3.03% Epsilon: 0.99 Action P
robabilities: [0.21136364 0.21515152 0.19621212 0.19924242 0.1780303 ] Traceback (most recent call last):
File “run_torch.py”, line 3, in
torch_training.multi_agent_training.main("-n 1000")
File “/home/mgewalti/aicrowd/baselines/torch_training/multi_agent_training.py”, line 188, in main
next_obs, all_rewards, done, _ = env.step(action_dict)
File “/home/mgewalti/anaconda3/envs/flatland-rl/lib/python3.6/site-packages/flatland_rl-2.0.0-py3.6.egg/flatlan
d/envs/rail_env.py”, line 476, in step
return self._get_observations(), self.rewards_dict, self.dones, info_dict
File “/home/mgewalti/anaconda3/envs/flatland-rl/lib/python3.6/site-packages/flatland_rl-2.0.0-py3.6.egg/flatlan
d/envs/rail_env.py”, line 536, in _get_observations
self.obs_dict = self.obs_builder.get_many(list(range(self.get_num_agents())))
File “/home/mgewalti/anaconda3/envs/flatland-rl/lib/python3.6/site-packages/flatland_rl-2.0.0-py3.6.egg/flatlan
d/envs/observations.py”, line 183, in get_many
self.predictions = self.predictor.get(custom_args={‘distance_map’: self.distance_map})
File “/home/mgewalti/anaconda3/envs/flatland-rl/lib/python3.6/site-packages/flatland_rl-2.0.0-py3.6.egg/flatlan
d/envs/predictions.py”, line 163, in get
raise Exception(“No transition possible {}”.format(cell_transitions))
Exception: No transition possible (0, 0, 0, 0)
Fails here also, but different error for single agent training:
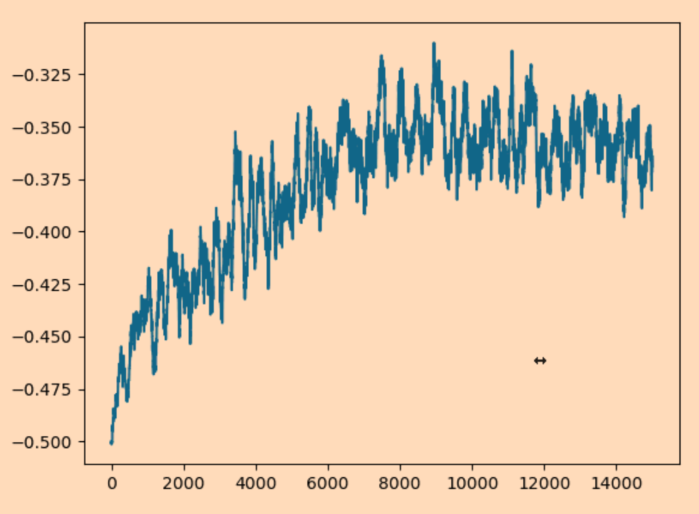
Training 1 Agents on (20,20). Episode 1771 Average Score: -0.401 Dones: 44.00%
Epsilon: 0.03 Action Probabilities: [0.0964351 0.19218464 0.15082267 0.22097806 0.33957952]/home/xarthur/Software/miniconda3/envs/flatland-rl/lib/python3.6/site-packages/flatland/envs/rail_generators.py:703: UserWarning: sparse_rail_generator: num_agents > nr_start_goal, changing num_agents
warnings.warn("sparse_rail_generator: num_agents > nr_start_goal, changing num_agents")
/home/xarthur/Software/miniconda3/envs/flatland-rl/lib/python3.6/site-packages/flatland/envs/schedule_generators.py:66: UserWarning: Too many agents! Changes number of agents.
warnings.warn("Too many agents! Changes number of agents.")
Traceback (most recent call last):
File "training_navigation.py", line 226, in <module>
main(sys.argv[1:])
File "training_navigation.py", line 195, in main
done_window.append(tasks_finished / env.get_num_agents())
ZeroDivisionError: division by zero
@mlerik
I have to say the current starting guide is really not well tested and creates so many glitches for beginners of this competition.
Please test and update the baseline repo and help us understand the environment so that we can contribute more.
Thank you for brining these bugs to our attention. I have unfortunately been offline and haven’t had time to look into it. Our team is working on fixing it and we will provide an update asap.
We will also improve the documentation to make the challenge more accessible. We believe the problem at hand is very interesting and hope that many of you enjoy the challenging task.
The second bug you reported is due to instabilities in the level generator. There were no Trainstations and thus no agents created in that environment.
We are working hard on fixing instabilities in the new level generator. Will push an update this week.
It seems that the generator made a map with an illegal transistion map. I will look into this as well. Could you provide any futher information about what file you ran? and what parameters you used?
I ran the vanilla multi_agent_learning.py from a freshly cloned baseline repo.
All I did is add a script outside the torch directory to import and the run the file.
Training 1 Agents on (20,20). Episode 1771 Average Score: -0.401 Dones: 44.00%
Epsilon: 0.03 Action Probabilities: [0.0964351 0.19218464 0.15082267 0.22097806 0.33957952]/home/xarthur/Software/miniconda3/envs/flatland-rl/lib/python3.6/site-packages/flatland/envs/rail_generators.py:703: UserWarning: sparse_rail_generator: num_agents > nr_start_goal, changing num_agents
warnings.warn(“sparse_rail_generator: num_agents > nr_start_goal, changing num_agents”)
/home/xarthur/Software/miniconda3/envs/flatland-rl/lib/python3.6/site-packages/flatland/envs/schedule_generators.py:66: UserWarning: Too many agents! Changes number of agents.
warnings.warn(“Too many agents! Changes number of agents.”)
Traceback (most recent call last):
File “training_navigation.py”, line 226, in
main(sys.argv[1:])
File “training_navigation.py”, line 195, in main
done_window.append(tasks_finished / env.get_num_agents())
ZeroDivisionError: division by zero
This bug should be fixed. Just checkout latest version from master trunk.
Thanks for the fast response.
After a first test, it seems that we still get the error. We do observe a difference between single and multi core machines, as the execusion is parallel: on multi core machines, the error occurs much faster.
Thanks for reporting the bugs and running the tests. It seems odd that training would not result in higher percentages than 50%. The task with only one agent and no stochastic events should be solvable just like in earlier versions of Flatland. I will look into this and check that there is no bug in the tree observation or the observation normalization.
We will soon push a fix to the bugs in Flatland 2.0 which will again allow you to install through pip.