
model llama3 70B can not use, Storage overflow.
@CPP : The available storage on the evaluation servers has been increased to 250 GB. Please try re-submitting the same solution again.
Please also be mindful that you will not be able to fit the unquantized llama 3 70B in GPU mem available in 4xT4 GPUs.
@aicrowd_team This T4 GPU inference speed is a bit slow, and a llama 3 8B inference has a timeout error, is this normal?
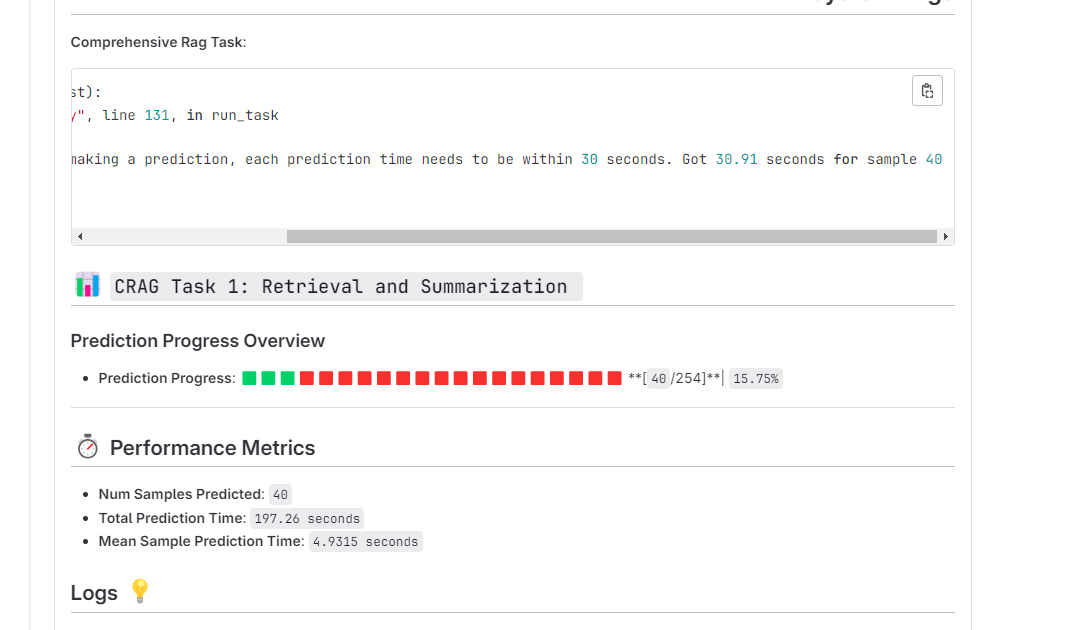
@CPP : It seems in this particular case, the mean sample prediction time is well below the limit of 30s, it was probably just one sample which exceeded the 30s limit. Might make sense to reduce the max_new_tokens for your model ?