Hi all, I found some problems with the datasets for Task 1.
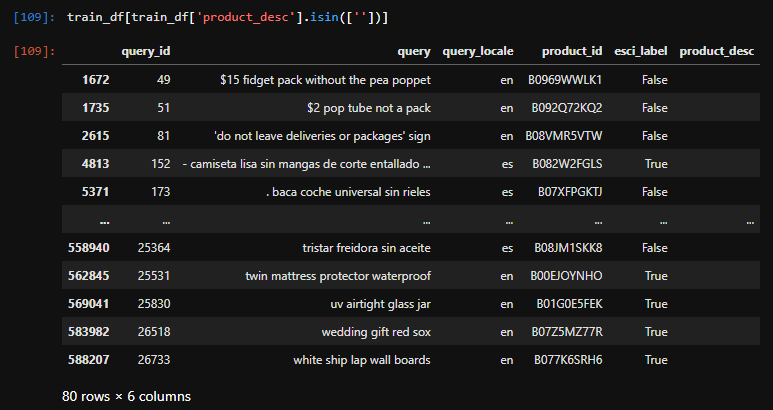
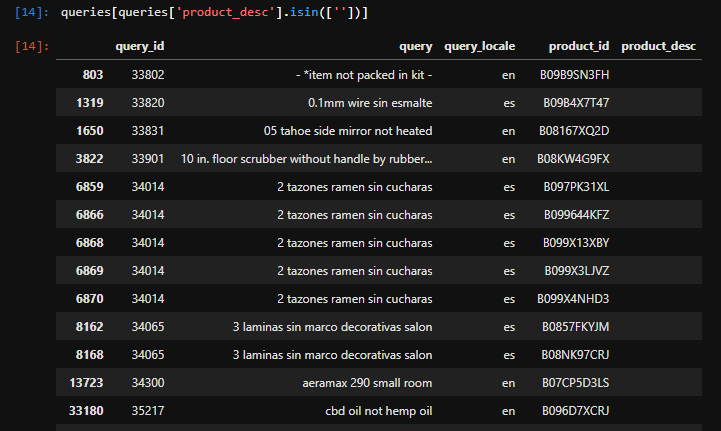
1st: Training data has annotated query/product pairs, whose products are empty in all fields.

2nd: The same is observed on the test set which is the major problem, as we have no basis on how to rank them.
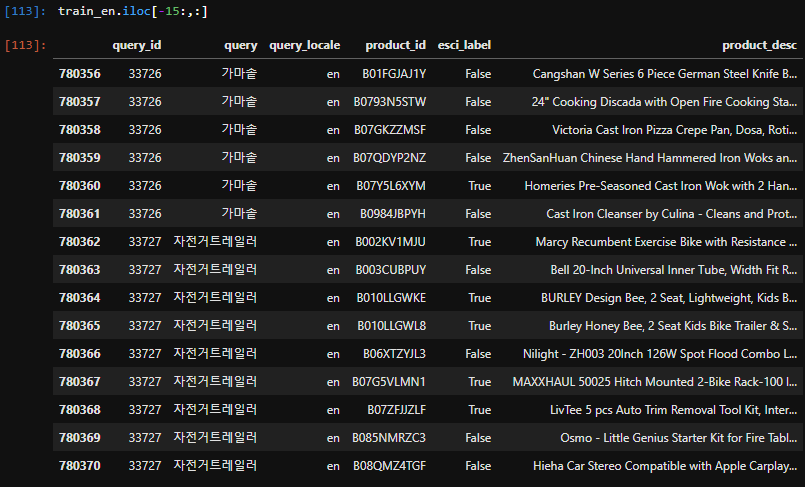
3rd: Back on the training set, there are some Korean, Chinese and Arabic queries marked as English.
Let me know if you’re not able to reproduce and I’ll provide the code.
3 Likes
The same issue I’ve also found.
1 Like
Hi,
Anybody from the AIcrowd Team had a chance to take a look at the issue?
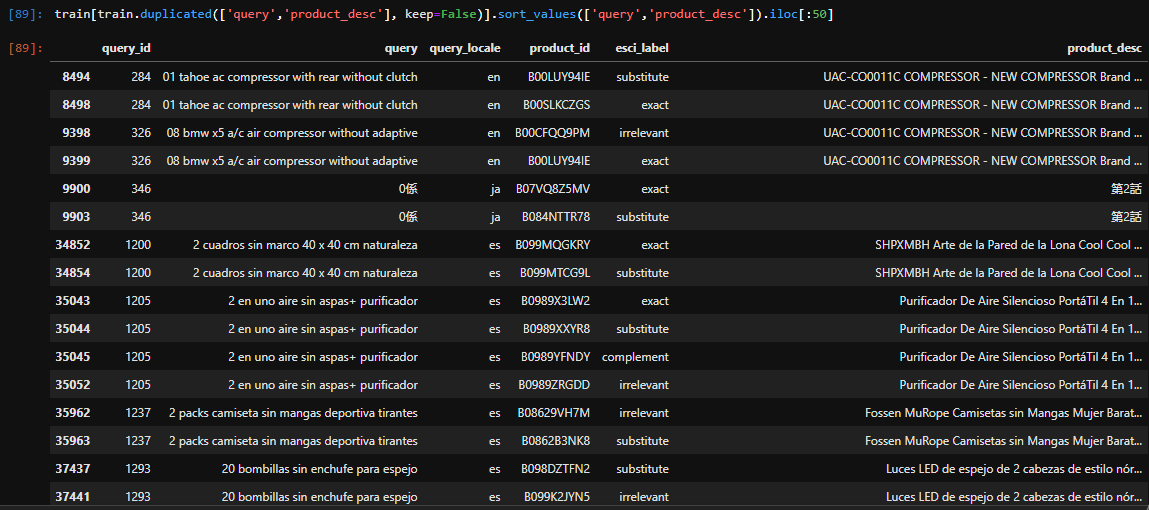
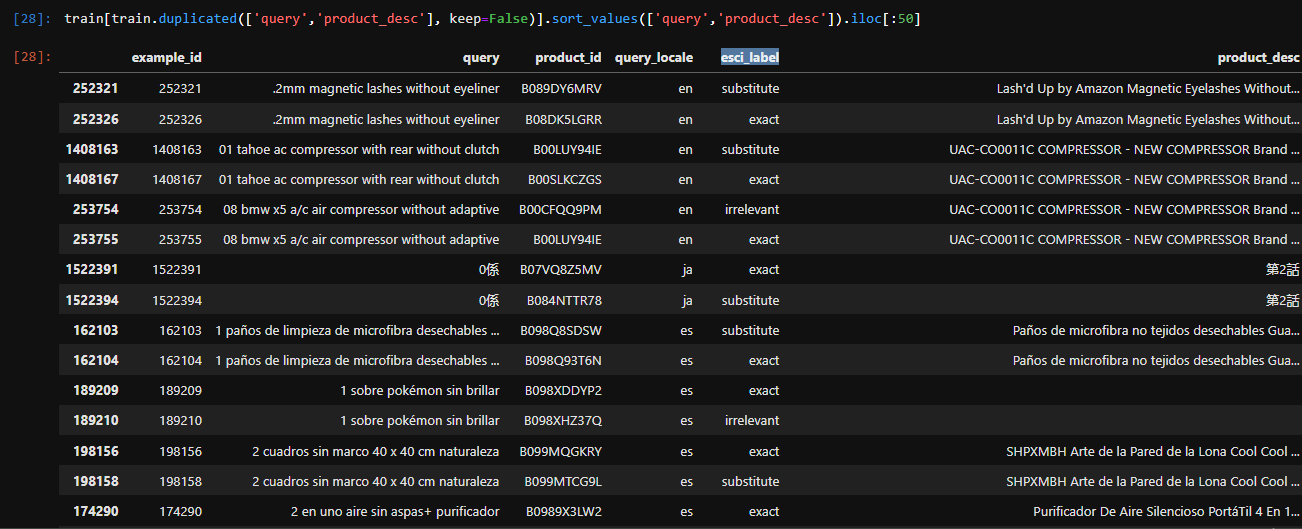
I also found out that on both task1 and 2 training sets, there are duplicates of annotated query/product pairs with different “esci_label”, including pairs that are annotated with both “exact” and “irrelevant” labels.
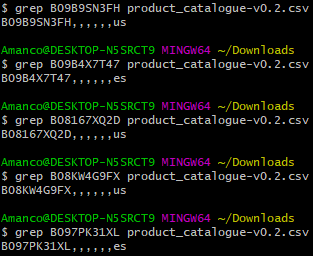
Although they posses different "product_id"s, when concatenating all fields from product_catalogue-v0.2.csv, they end up with the exact same description.
From task1:
From task2:
2 Likes
Hi All,
Thank you for bringing this to our attention. After discussing internally, here are our recommendations and action items for the issues identified on this thread.
Different product_ids have the same description
We acknowledge this observation, and after an internal discussion confirm that this is a result of the real-world and noisy nature of the dataset, and we will accept the fact that there will be some clusters of product_ids which will have the same product description. When generating the predictions for a specified task, your models should continue treating them as separate product_ids (with the exact same characteristics). The emergent effect of having an ideal model would basically then mean : In the Query-Product Ranking task, both the product_ids will be very closely ranked. In case of an Multiclass Product Classification task, both the product_ids (when having the same query and query_locale) will have the same ESCI label predicted. In case of the Product Substitute Identification task, both the product_ids (when having the same query and query_locale), will have the same substitute label predicted.
Some products have NaN for description
We acknowledge this issue, and Products with NaN for description etc will be ignored during the evaluation from the test set in the subsequent rounds and for the final leaderboards.
query_locale does not match the query language
The query_locale in the dataset is determined by the region in which the query was made, and hence it is possible that the actual language used in the query might be different from the query locale. Our expectations are anyway to encourage multi-lingual models.
Conflicting ESCI lables for <query, locale, product> pairs.
The ESCI labels for a <query, locale, product> pairs are currently determined by aggregating the majority votes of multiple human annotators for a given <query, locale, product> pair.
As mentioned above, multiple product_ids currently contain the same product description in some cases.
A small subset of those have conflicting ESCI Labels. We acknowledge the issue, and on closer inspection, we realized that the product descriptions in those cases do not capture the entire product characteristics, and hence different groups of human annotators have diverging consensus on what the final ESCI label should be. This is a result of the real-world and noisy nature of the dataset, and we will leave these as is.
Best,
Mohanty
2 Likes