Why did the statuses of my submissions #289776, #289706, #289611, #289670, and #289549 all change from “Generating Predictions” to “Preparing to Generate Predictions” partway through, and then stuck?
I think 289776 eventually failed due to timeout.
289706 somehow answered a None and caused the evaluator to fail
2025-06-18 12:41:05.661 __main__.AIcrowdError: Error from evaluator: argument 'input': 'NoneType' object cannot be converted to 'Sequence'
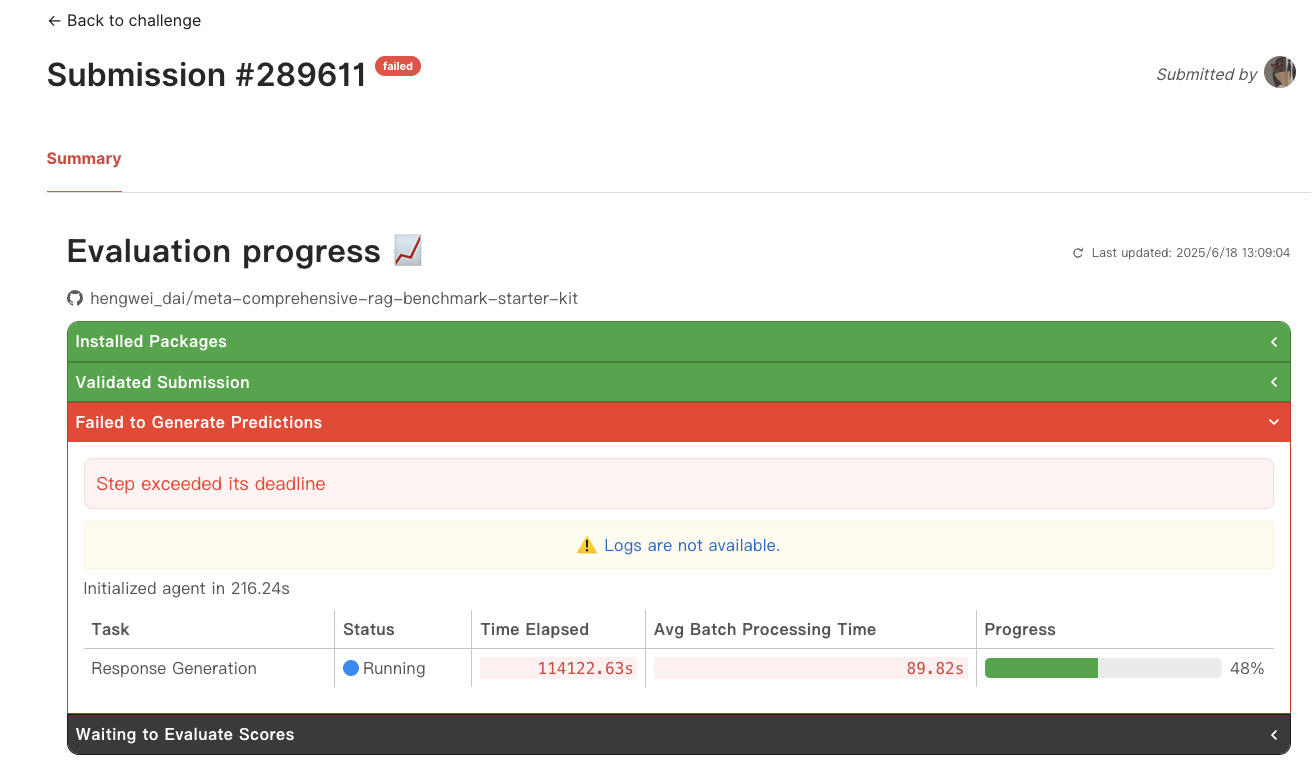
289611 somehow never started inference. We will re-run that and will still be counted valid for R2.
289670 and 289549 failed similarly as 289706.
Thank you for your response. After careful investigation, we believe the root cause lies in platform-side resource constraints, which lead to reasoning suspension and subsequent timeouts. Many other submissions likely encounter the same issue, and the specific reasons are as follows:
-
Take Submission 289776 as an example: it uses exactly the same code and configuration files as previous successful submissions (289544, 289499, 289369). All employ inference based on the
transformerslibrary, with only the LORA model weights changed. The weight configuration files are entirely consistent, so technically, there should be no difference in inference logic. Additionally, our code strictly limits the inference time to 10 seconds per test sample—if a timeout occurs at the code level, it directly outputs “I don’t know.” The fact that timeouts still occur suggests only one possibility: the platform’s testing environment suspends the process midway, but the elapsed time is still counted toward the total duration, causing the timeout. -
Furthermore, Submission 289611 showed inference progress on the page, and it, along with submissions 289670, 289549, and 289706, all experienced reasoning suspension issues (status transition from “Generating” to “Prepared to Generate” but then some of them changed back to “Generating” again but all faild finally). Unlike the
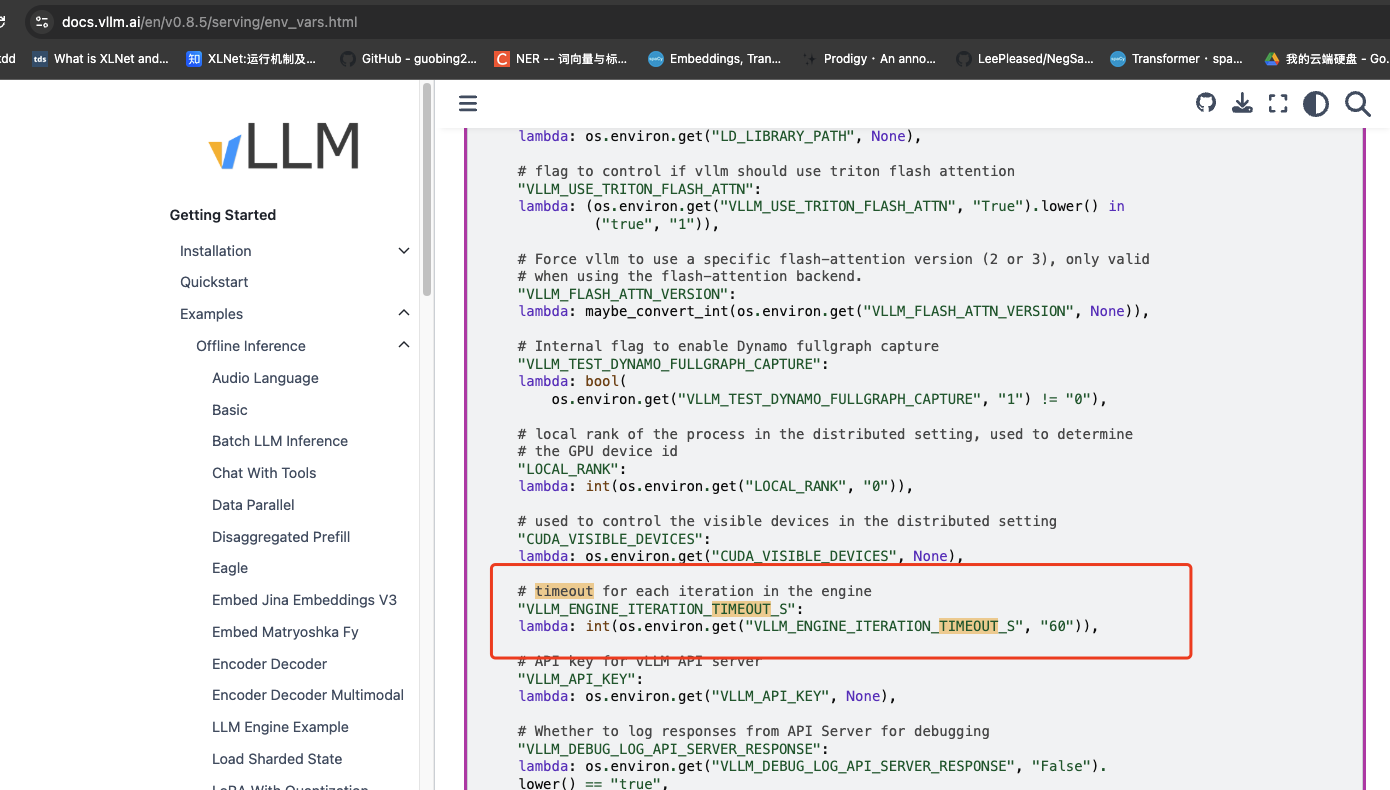
transformerslibrary, thevllmlibrary has a default 60-second timeout limit, which would trigger an exception if exceeded—this may explain why “None” is returned. Therefore, we kindly request staff to further investigate whether system-level factors are involved.
In summary, we had not considered the possibility of temporary reasoning suspensions (other than code-level timeouts) and did not implement corresponding countermeasures, leading to submission failures. We believe many failed submissions share this issue and sincerely urge the platform to carefully address it. On behalf of our team and all participating teams facing similar challenges, we extend our deepest gratitude for your attention.
3 Likes
Hi @hengwei_dai,
Thank you so much for taking the time to investigate and share such a detailed analysis. We completely understand how frustrating it must be to run into these kinds of issues, especially after putting in considerable effort to debug the failures across multiple submissions. We truly appreciate the depth of your diagnosis and want to assure you that we’re here to help—however much effort it takes.
Submission 289776 – Timeout Logs
Here are some of the key snippets from the logs showing how long each call to batch_generate_response took:
2025-06-18 02:51:29.948 | INFO | __main__:run_with_timeout:164 - Executed batch_generate_response in 118.05116105079651 seconds
2025-06-18 02:51:33.025 | INFO | __main__:run_with_timeout:154 - Running batch_generate_response with timeout 160
...
2025-06-18 02:57:20.037 | INFO | __main__:run_with_timeout:154 - Running batch_generate_response with timeout 160
2025-06-18 06:00:39.459 | INFO | __main__:run_with_timeout:164 - Executed batch_generate_response in 158.9750416278839 seconds
2025-06-18 06:00:42.298 | INFO | __main__:run_with_timeout:154 - Running batch_generate_response with timeout 160
2025-06-18 06:03:22.298 | INFO | __main__:run_with_timeout:164 - Executed batch_generate_response in 160.0000810623169 seconds
As you can see, one of the invocations precisely hits the 160-second timeout. The very next step took more than 160s and the evaluation failed.
Final Error Traceback
The submission fails with the following traceback:
Traceback (most recent call last):
...
File "/aicrowd-source/agents/single_rag_agent10v5.py", line 898, in batch_generate_response
output = self.batch_images_enhanced_response(
File "/aicrowd-source/agents/single_rag_agent10v5.py", line 772, in batch_images_enhanced_response
generate_ids = self.llm.generate(
File "/usr/local/lib/python3.10/site-packages/peft/peft_model.py", line 823, in generate
return self.get_base_model().generate(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/transformers/generation/utils.py", line 2465, in generate
result = self._sample(
File "/usr/local/lib/python3.10/site-packages/transformers/generation/utils.py", line 3434, in _sample
outputs = model_forward(**model_inputs, return_dict=True)
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/transformers/utils/deprecation.py", line 172, in wrapped_func
return func(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/transformers/models/mllama/modeling_mllama.py", line 2125, in forward
outputs = self.language_model(
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/transformers/utils/deprecation.py", line 172, in wrapped_func
return func(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/transformers/models/mllama/modeling_mllama.py", line 1929, in forward
outputs = self.model(
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/transformers/models/mllama/modeling_mllama.py", line 1789, in forward
layer_outputs = decoder_layer(
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/transformers/models/mllama/modeling_mllama.py", line 1789, in forward
layer_outputs = decoder_layer(
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/transformers/models/mllama/modeling_mllama.py", line 899, in forward
hidden_states, self_attn_weights, present_key_value = self.self_attn(
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.10/site-packages/transformers/models/mllama/modeling_mllama.py", line 781, in forward
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
File "/usr/local/lib/python3.10/site-packages/transformers/models/mllama/modeling_mllama.py", line 650, in apply_rotary_pos_emb
q_embed = (q * cos) + (rotate_half(q) * sin)
File "/usr/local/lib/python3.10/site-packages/transformers/models/mllama/modeling_mllama.py", line 624, in rotate_half
return torch.cat((-x2, x1), dim=-1)
File "/aicrowd-source/launcher.py", line 150, in _timeout_handler
raise TimeoutError("Operation timed out")
__main__.TimeoutError: Operation timed out
How Timeouts Are Raised
We use signal-based timeouts. Here’s a simplified view of how they work in the platform:
def run_with_timeout(fn, *args, timeout_duration=1000, **kwargs):
...
signal.alarm(timeout_duration)
try:
return fn(*args, **kwargs)
finally:
signal.alarm(0)
Based on this and the logs, the submission did indeed hit the configured timeout while generating predictions.
Other Submissions (289670, 289549, 289706)
All of these failed due to the same timeout issue.
The NoneType errors that followed are a side effect of how our evaluation infrastructure propagates errors. Specifically:
- The agent runs in an isolated runtime.
- When the agent method exceeds the timeout, we terminate the agent instance.
- The evaluator, which runs separately, expects a response and treats the lack of it as
None, leading to the downstreamNoneTypeerrors in logs.
On “Reasoning Suspension”
You were right in identifying what appeared like reasoning suspension. Our system relies on spot nodes for evaluation. When one of these nodes gets reclaimed, we spin up a new one, reinitialize the agent, and retry the last pending request (like batch_generate_response) i.e. the entire batch is replayed.
For stateless implementations of batch_generate_response, this is usually fine. But if your submission caches internal state between calls, that context may be lost in the new instance.
We know this isn’t ideal and truly empathize with how this impacts your workflow. We’re here to support you through these issues—please don’t hesitate to reach out again if you’d like to further debug.
1 Like
Thank you very much for your detailed technical analysis and transparent explanation regarding our submission issues. This is crucial for us to identify the root cause.
In case your submission emits logs that can further help, let us know. We will clean up any dataset related log lines and share it with you.
Thank you for your support. We’ve implemented step-level timing calculations for each sample in our code. Could you kindly export the inference-time print logs for the last batch that caused timeouts in submissions 289776 and 289706? Please remove any dataset-specific content. We would be extremely grateful if you could share the sanitized log outputs via message.