With conversations like Do you trust your Leaderboard Score? bringing up the topic of how reliable the public leaderboard score is compared to local CV, I thought I’d add some experimental data to help us guess how large the shakeup might be.
The setup is simple. We generate a test set with the same class distribution as the validation set (I made mine 4x the size of val for 1448 records). We train a model on the rest of the data. We then score said model on ~60% of the test set and again on the remaining ~40%, storing the results. It’s the same model, so we’d expect similar scores… but with relatively small test sets we’d expect some variation. The key question: how much variation should we expect?
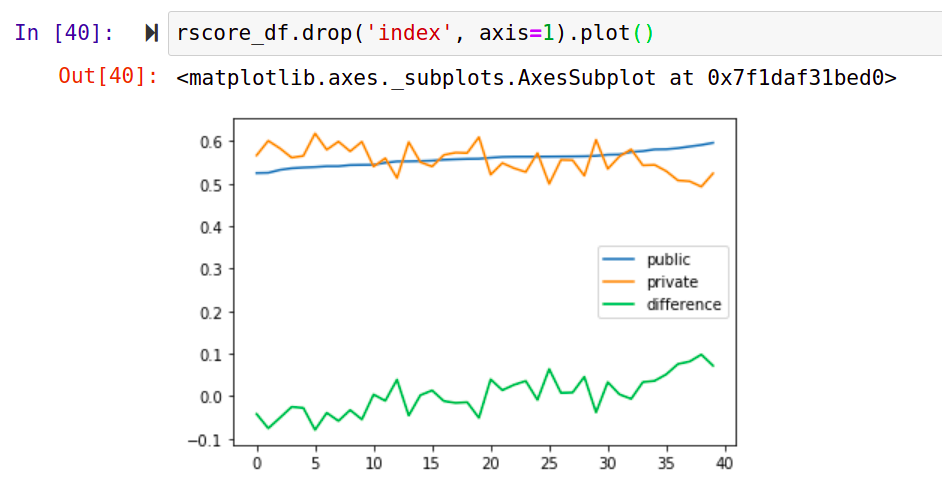
Running the above experiment 100 times and storing the results gives us some data to try and answer this question. For each run I record the ‘public leaderboard’ score, the ‘private leaderboard’ score and the difference between the two:
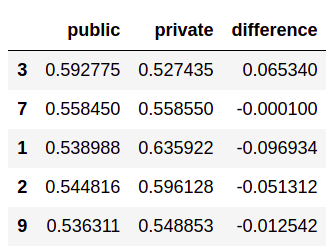
In some cases, the difference is as large as 10% - especially significant since the difference between #20 (me, as it happens) and #1 on the public leaderboard is less than 2%. Here’s the distribution of the difference as a percentage of the lower score across 100 runs:
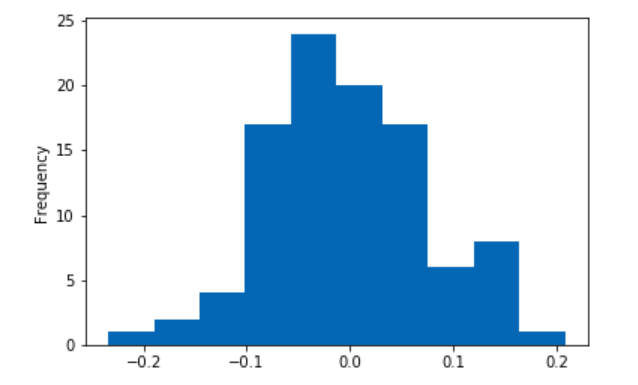
Now, I’m only training a single model for these tests - an ensemble might make fewer extreme errors and thus be less sensitive to noise. But even so, I think this experiment confirms what we’ve been thinking and points to an obvious takeaway:
The public leaderboard score gives you an idea of how well a model does based on one fairly small test set that might differ from the private test set. Better models will tend to get better scores, sure. But I think 1) Local CV is a must and 2) we can expect to see individual submissions getting fairly different scores on the private set, probably resulting in a bit of mixing on the LB. My hunch is that strong models that did well on the public set will still do well on the private set, so I’m not expecting #1 to drop to #30. BUT, those of us fighting for 0.01 to gain a few spots might be pleasantly surprised or a bit shocked in 4 days time depending on how things turn out.
A final thought: some people take randomness in an evaluation process like this to mean the competition is unfair. But everything we’re doing is based on noisy data and trying to draw conclusions despite the ever-present randomness. This is how things go. Make better models and your probability of winning will go up 
Good luck to all in the final stretch!