Hi,
I edited my notebook by adding new sections, and one of them is “Random”  .
.
When I build a model, I always add a random variable (from uniform distribution) to detect useless variables. I consider that all variables ranked under the random one are explaining noise. So I remove them  , and run a simpler and faster model
, and run a simpler and faster model  . As these variables were rarely used by the model, predictions and performances are very similar (but always a little lower
. As these variables were rarely used by the model, predictions and performances are very similar (but always a little lower  ). But the model is easier to implement.
). But the model is easier to implement.
Here, the rank is 39 !
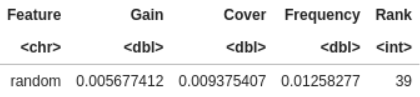
It mean I should remove a lot of variables  . I tested it: 2 successive models, one with all variables (LB logloss: 0.6136) and one with only 38 variables (LB logloss: 0.6147). Very similar …
. I tested it: 2 successive models, one with all variables (LB logloss: 0.6136) and one with only 38 variables (LB logloss: 0.6147). Very similar …
My feeling, and it was already discuss in a different post, is that random play a strong part in our submissions. Results and ranks will (randomly?) change on the 40% hidden dataset.
What do you think ? ![]()