Hi AIcrowd team — thanks for running the Global Chess Challenge.
I’m seeing what looks like a recent regression for Qwen3 (neuron.model_type=qwen3) on the Neuron/vLLM backend: at higher evaluator concurrency the model often produces garbled output, hits max tokens, and fails to reliably emit <uci_move>...</uci_move>, which causes immediate resignations and extremely high ACPL.
What changed (evidence from evaluation-state logs)
Looking at the config_snapshot field from GET /submissions/<id>/evaluation-state:
-
Submission 305873 (Dec 23):
config_snapshot.concurrency = 1-
finish_reason=stop(100%), reasonable completion lengths,<uci_move>present reliably - Overall ACPL ≈ 119
-
-
Recent submissions (Dec 24) now show
config_snapshot.concurrency = 4- Example 305972:
config_snapshot.concurrency = 4 -
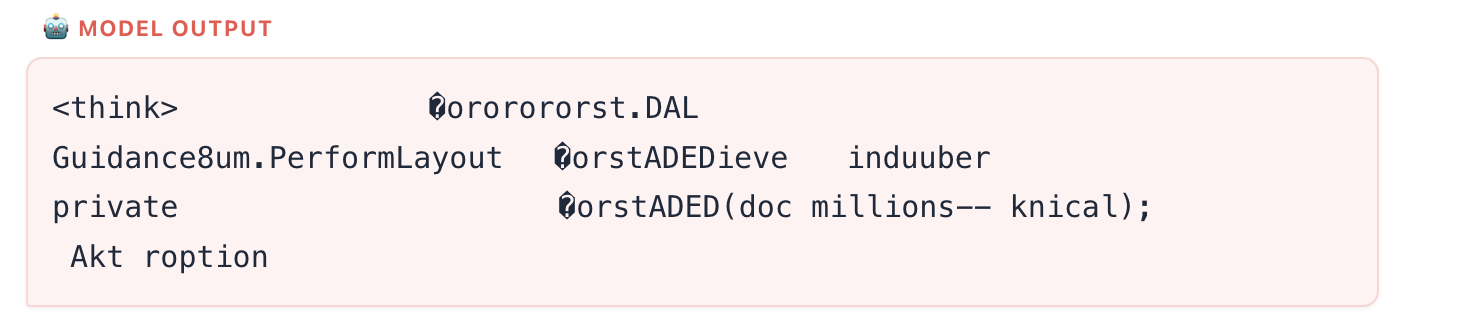
finish_reason=length~100%, completion tokens always hit the cap,<uci_move>rate ~25% - Outputs often look corrupted/garbled (binary-ish text), leading to resignations and ACPL ≈ 864+
- This submission used the same prompt settings as 305873 (
vllm.max_model_len=512,dtype=bfloat16,enforce_eager=true,max_tokens=64).
- Example 305972:
I also tried explicitly requesting --num-games 1 / --concurrency 1 in aicrowd submit-model, but the resulting evaluation logs still show concurrency=4 (and num_games=4), suggesting these are being overridden by the evaluator (e.g. submission 305974).
Questions
- Did the evaluator concurrency change recently from 1 → 4 for this challenge?
- If so, is there a recommended configuration (vLLM/Neuron flags or supported submission fields) to keep Qwen3 stable at
concurrency=4? - Is this a known Neuron/vLLM issue/regression for Qwen3 under concurrent request load?
I’m happy to provide additional req/resp snippets (showing finish_reason=length + corrupted outputs) if that helps debugging. If this should be handled privately instead of on the forum, let me know and I can share details via DM/support.
Thanks again for the challenge and for any guidance here.