Out of 4316 cases in the training set, only 3504 compound structures are unique. That means the training set contains 812 duplicate structures (18.81%). While that could be intentionally introduced noise, or even a decoy set, it is also quite common SMILES error and could be simply miss-annotations.
The implications are however severe, some of those contain also different flavor annotations.
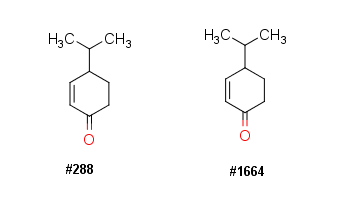
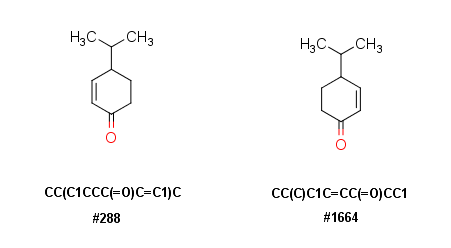
Compound #288 and #1664 are exactly the same. This could be a problem of unique SMILES codes, which was not used by the data providers, leading to multiple annotations. Or as mentioned before its noise or decoy intentionally introduced by the competition providers.
Either way, if the 812 duplicate structures have different flavor annotations, they have to be removed (garbage-in --> garbage out). Otherwise the trained model is false. If the annotations are the same, one compounds can be removed, in order not to overfit the data with the same component twice.
@Tobi, Chiral molecules like in pharmaceutical domain may have different behaviours. This is why you have those “chiral” SMILES. The chirality is very important (3D) and this is not duplicated data.
@guillaumegodin Thanks, the examples above (I corrected them) clearly show that no double bond or tetrahedral isomers are in the original SMILES code (#288 and #1664). According to Daylight, these are designated by “” and “/” for cis/trans and “@” and “@@” for E/Z isomers.
However the (original training) SMILES codes are different, and show a compound that is just mirrored (I corrected that), but has no stereoisomers in the SMILES itself. This is the original data:
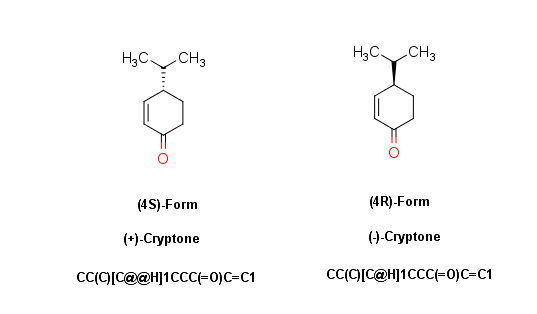
The correct way to describe the tetrahedral and double bond stereosimers would be by using the up and down bond or the “@” and “@@” signs in the SMILES code. But that is missing. The correct SMILES are in the figure below.
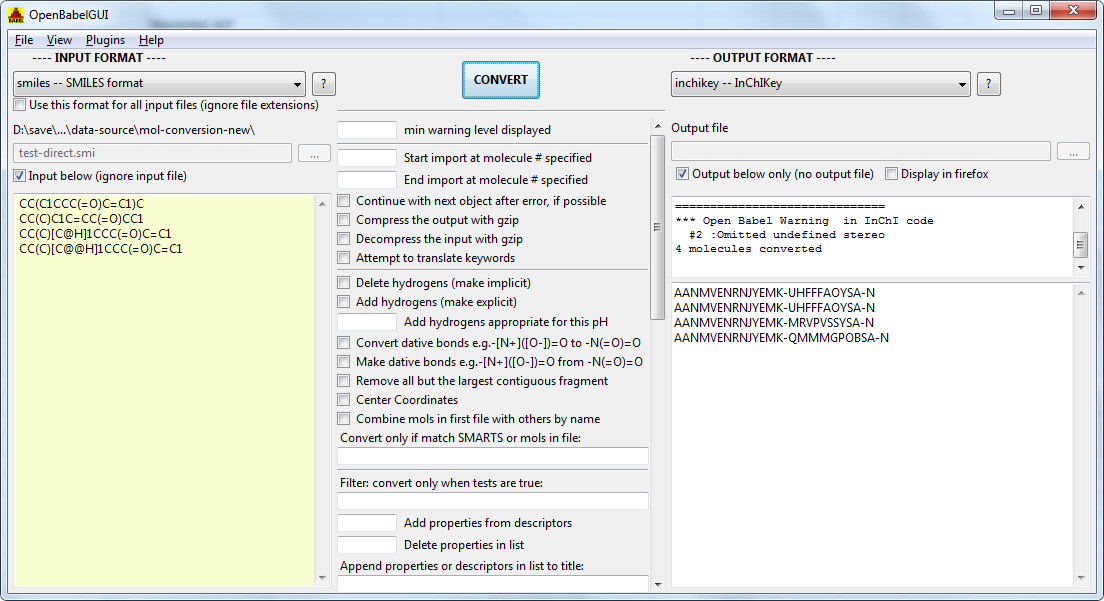
Also an additional independent analysis with topology analysis but different stereoisomers kept, came to a similar number 825 structures in the training set are exact duplicates. Maybe providing the correct stereo-isomer form in SD format would be helpful, or the structures are simply not correct. SMILES duplicates were tested in OpenBabel.
First, there is no duplicates. Second we used rdkit Inchi & smiles (we have canonical RDKit SMILES for the isolated stereoisomers, provided information is available and unambiguous) for double check, with multiple teams.
Another very important point canonical smiles is related to toolkit only so if you use another toolkit than RDkit, which is the most used across all AI papers > 60%, we will have other canonical representations due to other canonical procedures. Inchi is unique so you can use them to compare in any toolkit.
I played this game 5/6 years ago for fun: CDK vs RDKit in average have less than 10% identical canonical strings after the canonical procedure taking the same smiles as input for the two toolkits.
Inchi is available in RDkit anyway so double check is very easy!