Hi AIcrowd Team, just want to clarify something :
- In the post-purchase training phase,
# Create a runtime instance of the purchased dataset with the right labels purchased_dataset = instantiate_purchased_dataset(unlabelled_dataset, purchased_labels) aggregated_dataset = torch.utils.data.ConcatDataset( [training_dataset, purchased_dataset] ) print("Training Dataset Size : ", len(training_dataset)) print("Purchased Dataset Size : ", len(purchased_dataset)) print("Aggregataed Dataset Size : ", len(aggregated_dataset)) DEBUG_MODE = os.getenv("AICROWD_DEBUG_MODE", False) if DEBUG_MODE: TRAINER_CLASS = ZEWDPCDebugTrainer else: TRAINER_CLASS = ZEWDPCTrainer trainer = ZEWDPCTrainer(num_classes=6, use_pretrained=True) trainer.train( training_dataset, num_epochs=10, validation_percentage=0.1, batch_size=5 ) y_pred = trainer.predict(val_dataset) y_true = val_dataset_gt._get_all_labels()
shouldn’t it be something like this?
trainer.train( aggregated_dataset , num_epochs=10, validation_percentage=0.1, batch_size=5 )
- Because the combined and different time budget, shouldn’t it be something like this?
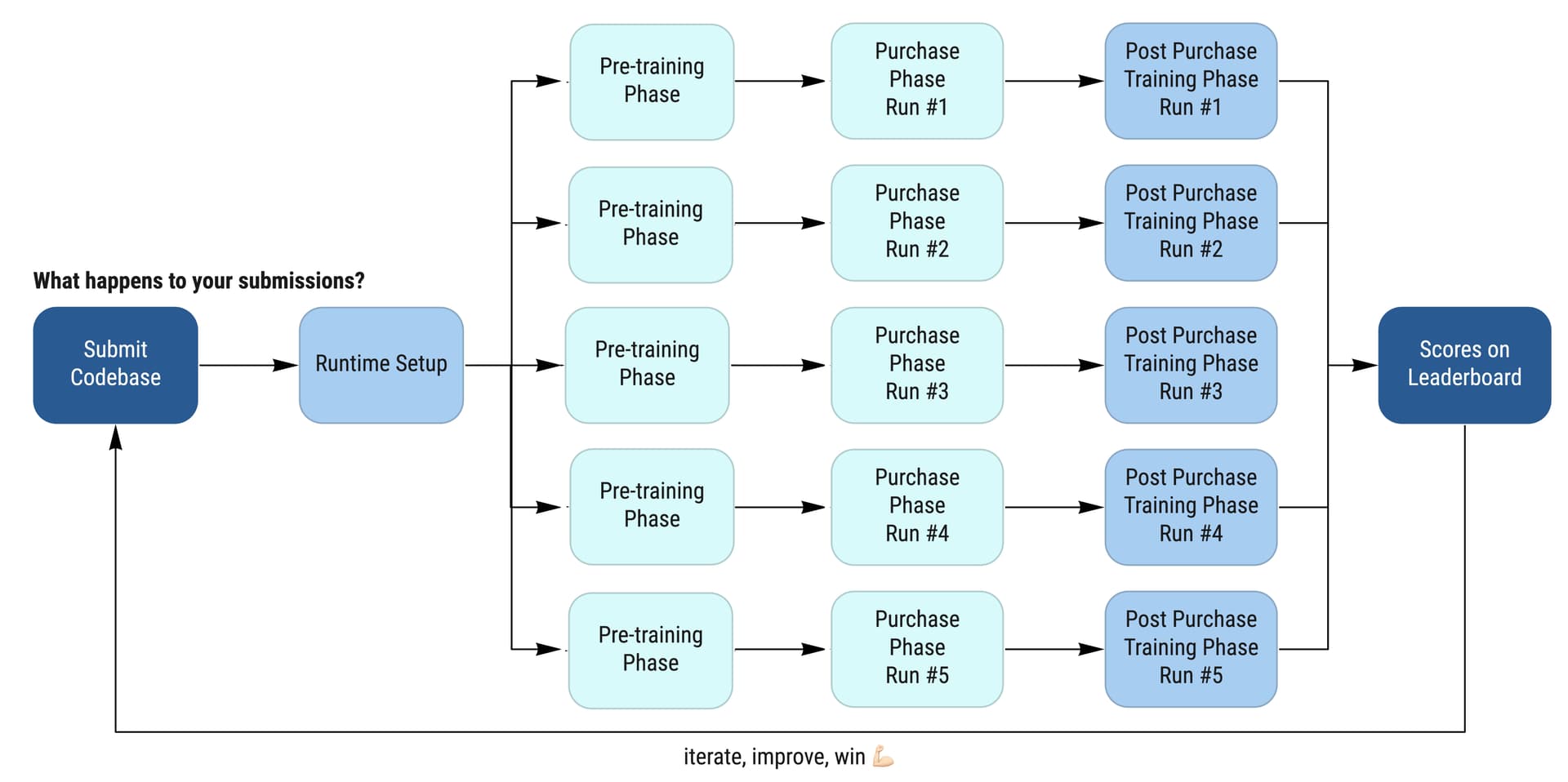
instead of the original diagram?
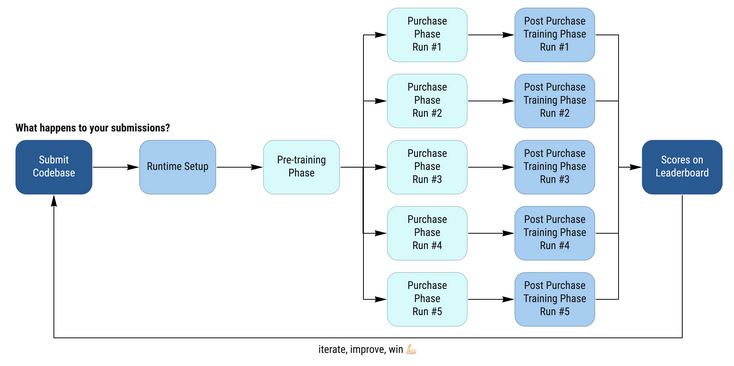
or did I assume it wrong?
Thanks.