Hi, after looking at the local_evaluation.py code. It looks like one would have to modify the OrderEnforcingWrapper so as to pass all the information through to a multi-agent coordinator.
On the other hand OrderEnforcingWrapper has this in its docstring
TRY NOT TO CHANGE THIS
So can we change this? or should we find another way to pass the whole information to a coordinator agent?
Hi @felipe_b, thanks for your question. Your title says ‘single coordinating agent’ but your text seems to be referring to ‘multi-agent coordinator’. Please, do you mind clarifying this before I answer your question? Are you wanting to use 1 agent to control all buildings?
So, how exactly do users pass information using OrderEnforcingWrapper?
There is no reward information passed with ObsDict or observation when the environment is stepped.
Hi @kingsley_nweye.Sorry. I am referring to a single coordinator, or as you put it a ‘multi agent-cooordinator’ . It should receive the information on the observations/action space for all the buildings.
Hi @felipe_b, thanks for clarifying. I don’t think that the current implementation of OrderEnforcingWrapper allows for a single-agent (aka central_agent in CityLearn) set up yet. @dipam please, is this something we can implement?
@kingsley_nweye no need to implement this as long as I can change orderenforcingwrapper.py it will be OK.
I saw @dipam answered on Dicord that we can manipulate the file as long as we respect the shape of the output.
Thank you very much @dipam . And I have another question are we guaranteed that the observation spaces are the same for all buildings?
Because if not I think , in the evaluation script, we should receive the observation_spaces (as well as the action spaces) and building information as in citylearn repo main examples
See
# Contain the lower and upper bounds of the states and actions, to be provided to the agent to normalize the variables between 0 and 1.
# Can be obtained using observations_spaces[i].low or .high
env = CityLearn(**params)
observations_spaces, actions_spaces = env.get_state_action_spaces()
# Provides information on Building type, Climate Zone, Annual DHW demand, Annual Cooling Demand, Annual Electricity Demand, Solar Capacity, and correllations among buildings
building_info = env.get_building_information()
Hey @felipe_b. The shape of the observations is common across all buildings however, the low and high limits for some observations e.g. net_electricity_consumption, solar_generation, e.t.c. are building specific. The action space shape and limits are common across all buildings.
Regarding accessing the building_info and observation_spaces, I have made them available via the obs_dict. You will need to update the environment to the latest version 1.3.3 to avoid a bug that was associated with retrieving building_info.
@dipam maybe there needs to be some additional refactoring to make these variables available to order_enforcing_wrapper?
Hi @desmond, I have fixed this error in the starter kit.
The rewards have been calculated within the environment step function all along. The reason for this error was an update to allow participants define their own reward function (see here).
Sorry about the confusion and I hoep this clears things.
Hi @kingsley_nweye,
Thanks for the prompt reply. I noticed there is the reward in the env. step function. However, since we cannot edit the local_evaluation.py. We could not get the access of it since it is omitted in the line observations, _, done, _ = env.step(actions)
Another question, when submitting, do we need to use the latest version of code or just whatever version that could run through your evaluation process?
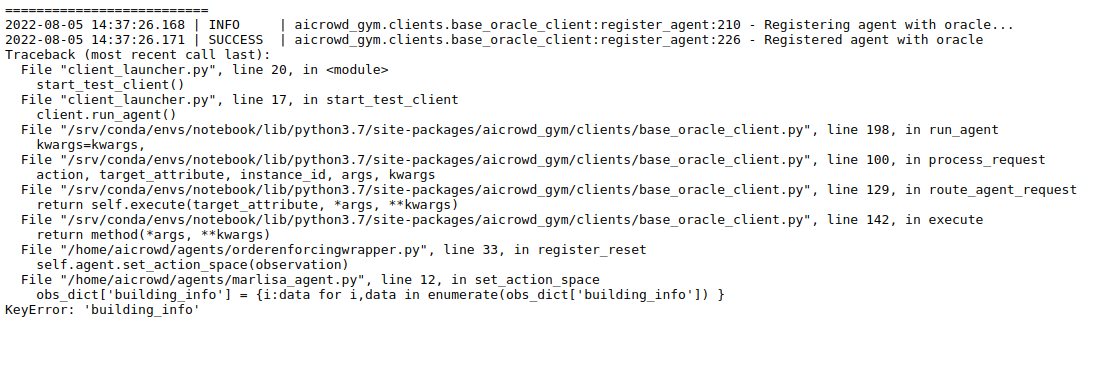
I just tried the updated version and got another error.
Starting local evaluation
Traceback (most recent call last):
File "local_evaluation.py", line 105, in <module>
evaluate()
File "local_evaluation.py", line 46, in evaluate
obs_dict = env_reset(env)
File "local_evaluation.py", line 30, in env_reset
building_info = env.get_building_information()
File "/home/hsinyu/anaconda3/lib/python3.7/site-packages/citylearn/citylearn.py", line 517, in get_building_information
building_info[building.uid]['solar_power_capacity'] = round(building.pv.capacity, 3)
AttributeError: 'PV' object has no attribute 'capacity'
Hi, we can obtain high and low limit of observations via observation_space, but how can we get the definition/meaining of the observations. Building_x.csv files are not direclty used as observation as I understand.
Hi @semih_tasbas. Thanks for your question. There are a couple of ways to identify the names of the observations. In the case that you are using a multi-agent setup; the order of the observations that have active:true in the schema.json will tell you what name maps to what observation. Another way to get the meaning of observations is to use the citylearn.Building.observations property that returns a dict e.g.:
env.buildings[0].observations
Also, see the docs for information about the ordering of observations at the env.observations level.
Hope these clarfiy things and sorry for the late response.
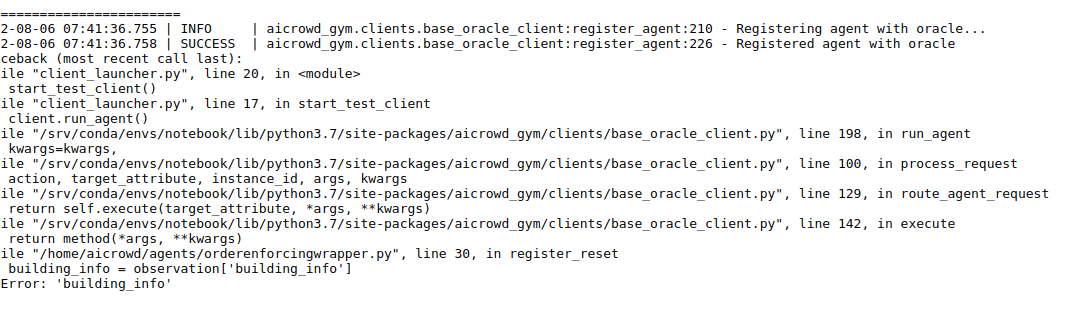
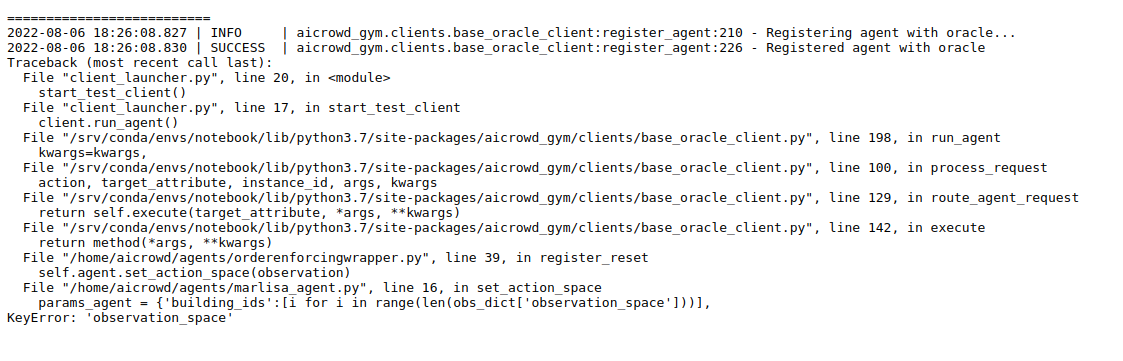
Hi @kingsley_nweye thank you for adding the building_info to the local_evaluation script.
I am trying to run Marlisa which uses building_info but I think that in production your evaluation is not passing along the building info
I am running thi code to duble check as soon as I get my submissions count refreshed. I will put it in the ordering wrapper to catch the bug in online evaluation
def register_reset(self, observation):
"""Get the first observation after env.reset, return action"""
action_space = observation["action_space"]
self.action_space = [dict_to_action_space(asd) for asd in action_space]
obs = observation["observation"]
self.num_buildings = len(obs)
#CHECK MISSING INFO
# I check that the dictionary contains the building_info.
building_info = observation['building_info']
for agent_id in range(self.num_buildings):
action_space = self.action_space[agent_id]
# self.agent.set_action_space(agent_id, action_space)
self.agent.set_action_space(observation)
return self.compute_action(obs)