Now that the private leaderboard is online, I am going to provide the details of my submission. Initially, I attempted to improve F1 accuracy using detection models, but they were not comparable with TOP LB, so I used yolov5 as a classification model for detected bbox, but the PyTorch implementation had some errors, resulting in poor performance and producing different results between cli evaluation and PyTorch infernce. After a few failed attempts, I learned that others had the same mIoU score for their submission, so I attempted with the Yolov 8-L classification model, which has a 70 LB f1 score. So, for detection, I utilized Yolov5-S with a CBAM layer in the last layer with an image size of 640, resulting in 233 filtered predictions. The Yolov5m6 with a transformer head and 1280 image size generated better results, but the inference time is very high, so I haven’t used this model for submission with classification models.
For Classification Task, I used this Colab Notebook with multiple modifications. I couldn’t figure out the LB difference, but then saw external dataset posts after the competition ended. So, external datasets are allowed, but external mosquito alert image datasets are not allowed.
The classification training details are mentioned in the shared notebook, and I used Wandb for experiment tracking and openvino for bigger models to fit an inference time of 2 seconds. There could be a slight difference between TPU and CPU inference.
Thank you to the organizers for hosting this competition. I have spent the past month and a half trying to build a single model to get to the top of the leaderboard. I have tried various models, including YOLOv8, YOLOv7, YOLOv5, DETR, and RT-DETR, but none of them have given me good leaderboard scores.
In the last 18 days, I decided to try image classification models. I was able to achieve a CV of 0.6 to 0.65 while training on the original data. I then trained only on the cropped images, which took my CV to 0.72 to 0.75. I was stuck here for a while, but in the final week of the competition, after the participants shared the additional data, I was able to improve my CV from 0.74 to 0.82-0.84.
I used YOLOv5m with a size of 640 for object detection and EfficientNetV2s with an image size of 384 for image classification. I used an 80-20 percent split for the evaluation.
what worked for me are training on cropped Images , larger image classification models and augmentations like cutout and cutmix
Looking forward to reading other top solutions where people reached lb of 0.9 and even their object detection models are pretty good!
Hi,
Thanks a lot to the organizers, sponsors and AICrowd team for this quite interesting challenge!
My solution that reached 3rd place on both public and private LB is based on two stages:
- Stage1: A mosquito bounding boxes detector model based on Yolo.
- Stage2: An ensemble of two mosquito classifiers models. First model is based on ViT architecture and second on EfficientNetv2 architecture.
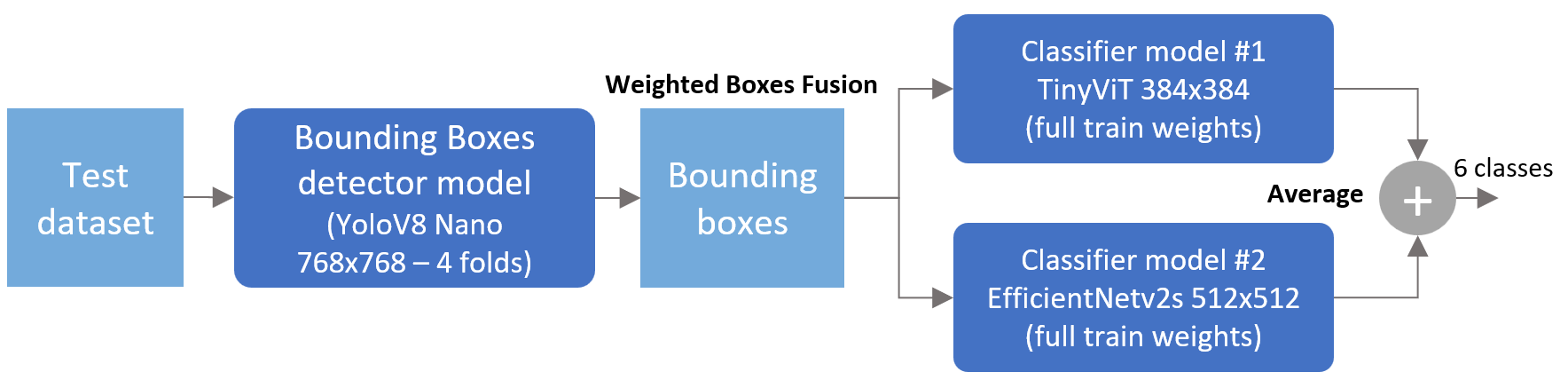
The two main challenges in this competition were the 2 seconds CPU per image runtime limit and the high imbalance for rare classes in the training dataset. Such constraints limit the total number of models we could ensemble, TTA options, image size and size of the possible models.
After several experiments, my conclusion was that a single model “on the shelf” that could do both bounding boxes + classification won’t perform as good as two dedicated separate models. For bounding boxes I’ve ensembled 4 YoloV8 nano models (converted to OpenVino to speed up inference) trained on a single class. For mosquitos I’ve trained two classifiers with different architectures and image size. I got some boost/stability on classification score with the following items in the training procedure:
- Hard augmentations including Mixup + CutMix
- Averaging weights with EMA
- Label smoothing
- Creating a 7th class (no mosquito) with background images generated from training images without mosquito. I believe that blood + fingers was prone to confuse the model.
- External data that brings more examples on rare classes. I’ve only used a limited subset of what was provided in the external datasets thread because I find it quite noisy.
Cross validation for each model single was F1=0.870/0.860 (best fold with 0.891). However, it was not possible to use them in inference due to time limit. So, I’ve decided to train a full fit model to benefit from all data in a single model. Basic ensembling of both classifiers (no TTA) reached 0.904 on public LB and 0.915 on private LB.
What did not work (or not improve):
- Increasing image size to 1024x1024 does not bring more information to the models
- Forcing the aspect ratio to 1.0 on resize did not help
- Single stage 6 classes Yolo model (both regular and RTDETR)
- Single stage 6 classes EfficientDet model
- SWA (last 5 epochs or best 5)
- Model pruning (to speed up inference)
- Post Processing: Add/remove margin to predicted BB
- Training based on mosquito bodies only. I’ve created a mosquito body extractor but my conclusion is that relying on head, thorax, and dorsal is not enough. We have predictive power in mosquito legs and wings. It might be obvious for the experts but from past experiences on other species it was worth trying.
Cheers.
Thank you for sharing your solution. Nice use of ensemble techniques.
Is your improvement score lower on that noisy external dataset due to the use of multiple small models?
Lower compared to other competitors? Possible, large models would have performed better for sure, but I’ve also removed a lot external data because I didn’t take time to implement a cleanup procedure. I’ve generated bounding boxes pseudo labels based on Yolo model high score confidence, everything below 0.7 confidence has been dropped.
We used a two-stage approach, similar to others. First, we detected the bounding boxes and then classified the images.
For detection, we trained a YOLOv8-s model (640x640). However, the YOLO model we trained performed poorly in the final evaluation, causing us to drop from 5th to 7th place. This could be due to the model overfitting or noisy annotations from the host (if the test annotations are similar to the provided annotations).
Once we detected the mosquitoes, we classified them by fine-tuning a CLIP ViT-L-14 model (GitHub - mlfoundations/open_clip: An open source implementation of CLIP.). To address the class imbalance, we oversampled the dataset and applied extensive data augmentation techniques, including blurring the image, adding elastic distortion, adjusting colors, and rotating, all the good stuff. Additionally, instead of relying on the host’s annotations for cropping the images, we used our own YOLO model annotations. We made this change because we noticed a discrepancy between our local evaluation and our submission score (maybe this discrepancy is due to overfitting). After some time, we realized that we used YOLO annotations during inference, but for training, we used the competition annotations. Therefore, after retraining the classifier with YOLO annotations, the gap disappeared. Similar to MPWARE, we used label smoothing and EMA. In the final week of the challenge, we incorporated additional data provided by Lux (‼️ External Dataset: 🗂️ Notice on Usage & Declaration - #4 by Lux) to further improve our score.
To summarize:
- We trained one model for detecting mosquitoes and another for classifying them.
- We addressed class imbalance through oversampling and extensive data augmentation.
- We applied label smoothing and EMA, similar observations as ([2212.06138] CLIP Itself is a Strong Fine-tuner: Achieving 85.7% and 88.0% Top-1 Accuracy with ViT-B and ViT-L on ImageNet).
- We used our detection model for cropping mosquitoes instead of relying on host-provided annotations.
- We incorporated extra data from Lux.
We built a simple Hugging Face space for interacting with our solution (Mosquito Detection - a Hugging Face Space by hca97).
It’s insightful to see your iterative process with detection models and the switch to YOLOv8-L. Your use of external datasets and clarification on allowed content is noted. Good call on experiment tracking with Wandb and using OpenVINO for efficient inference. Best of luck with your submission!
Cheers,