Hey there!
This far into the competition, and having some time off, I want to initiate a discussion, so that this forum is more than just:
- debugging issues
-
bugging @alfarzan about evaluation metrics/leaderboard …

… Are you overlooking it? 
The first part of this competition is a relatively normal modeling challenge; tabular, good exposure, a few handfuls of variable.
…
And then there’s a 2nd portion that I believe most might overlook… the pricing strategy.
I know I am… …guilty! 
Creating my own internal leaderboard 
Having several models on hands, today I tried to actually look at pricing, instead of simply RMSEs.
- 15 models, with diverse algorithms,
- 68.5k test policies,
- lowest price wins.
Calculated profit, loss_ratio, closing_ratio and avg_premium.
Results 
First off, interesting to see how spreaded was the market share. (closing ratio).
There’s no single clear winner..
Also very interesting to see some models winning significantly lower avg_premiums (model #13) (on significant volume) . Tells me it’s larger risk pricing is not competitive at all.
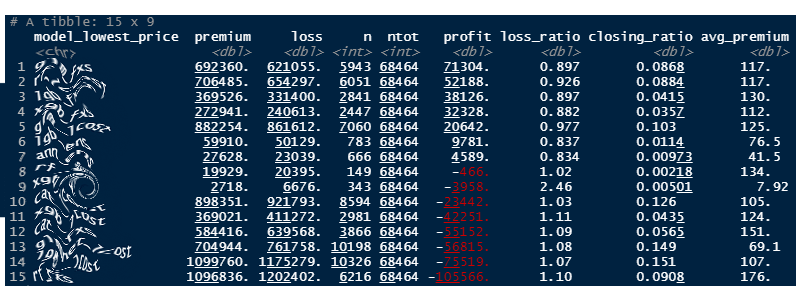
But can I really take anything away from this? … this is a just sample, and limited data to create enough folds.
…ugh .  randomness in insurance is challenging…
randomness in insurance is challenging…
And you? 
How are you feeling these days… Are you overlooking the pricing?
Or have you all been developing price optimization, simulating markets and competitor prices? 

Side note:
I’m guilty of having spent way too much time on this project… 
I’m curious about others? Were you caught in more than you would’ve expected?
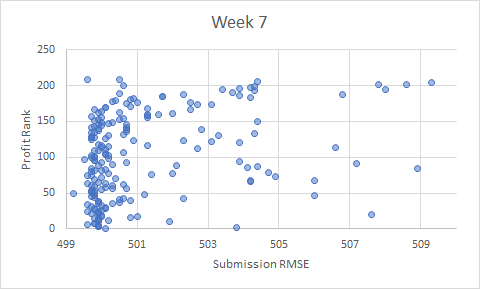
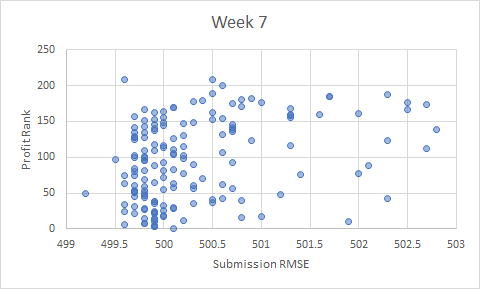
 , but I assume that’s your intent.
, but I assume that’s your intent. (the two charts are based on the same data, but the x-range has been adjusted):
(the two charts are based on the same data, but the x-range has been adjusted):