Hi everyone!
I am Sergey, and I am a machine learning researcher in Gazpromneft, a Russian Oil&Gas company. I am working in the field of seismic exploration for some time now, and this hackathon is a perfect chance to showcase our skills to the rest of the world. Nevertheless, it is our very first time working with such type of structures on seismic data, so it is as new to us as to any other ML practitioners.
In this post, I will try to cover everything that I’ve done so far to produce submissions for this contest: from data exploration to generating predictions, with descriptions of pretty much every line of code. Also, as I had enough time for testing various approaches to work with seismic data, I will share them as well: libraries and tricks to use for geological analysis.
Currently, I use our own servers to run my experiments on; in the next few days, I will gradually transfer everything to COLAB to share the progress. That can take some time, so be sure to like this post and check it for updates!
0. seismiQB
To solve various tasks of seismic interpretation, we’ve developed an open-sourced Python framework seismiQB. It is capable of:
-
Working with seismic cubes at any stage of processing: pre-stack, post-stack, and 2d data. It may not be the most flashy thing from the standpoint of this contest, but allows us to conveniently work with any data we are provided with. Not only that, but our custom format of data storage can access data up to 30 times faster than regular SEG-Y can.
It is designed to work with 100+ GB cubes, so may not be that necessary for the needs of this competition where it is easier to load everything into memory.
-
Creating pipelines of data generation. Apply augmentations on the fly with a chosen parallelism engine: for example, if you have code that transforms one image from your batch, we provide a method of applying them in parallel to every image in the batch via
multithreading, multiparallel or async.
-
Configuring sophisticated neural networks with just a few lines of code. We’ve written our custom wrappers for
TensorFlow and PyTorch, which allow us to use short configs to define even the most complex architectures. Our model zoo has a huge number of pre-implemented architectures, ranging from plain old UNet to the DeepLab v3+ with all the modern bells and whistles. If you don’t like any of them, it is easy to build your own model from pre-defined blocks like ResNet block, ASPP, Xception block, etc.
-
Training on arbitrary 3D crops, sampled from the cube according to the desired distribution. We can work with any shapes and have rich tools to cut the data from cubes and merge individual crops back together: that allows us to make overlapping predictions to improve the overall quality of our models.
-
Exploring hyperparameter space by running a number of experiments simultaneously. With all the wealth of parameters that is presented by our framework, we need to make a lot of experiments to narrow the exact architecture down. To this end, we have a special module, that runs them in separate processes, while keeping a detailed log of each of them.
-
Profiling of pretty much everything. If you do something – you can time it and check the memory consumption. As we write production-quality code that is used by our geologists on daily basis, we optimize everything to the nth degree. Our tools enable us to do so.
Our code has a lot of documentation inside, but if you have any questions about it, be sure to contact us! We also have dedicated libraries for seismic processing and petrophysics.
As I already said, we have never worked with facies like in this challenge previously: the tasks that we tackled so far are:
- Horizon picking
- Horizon extension and enhancement
- Estuaries detection
- Faults extraction
- Reef outlining
For most of them, we have openly available notebooks that demonstrate in great detail, how to solve the problem. We are advocates of a rigorous approach to our researches, so each of them follows our company-wide standard. Be sure to check them out!
In this contest, unlike any of our previous affairs, we need to do cube-to-cube prediction: to this end, I had to implement some new primitives, but that relates mostly to data loading. From the moment we have images and segmentation masks, it is business as usual.
1. Exploratory data analysis
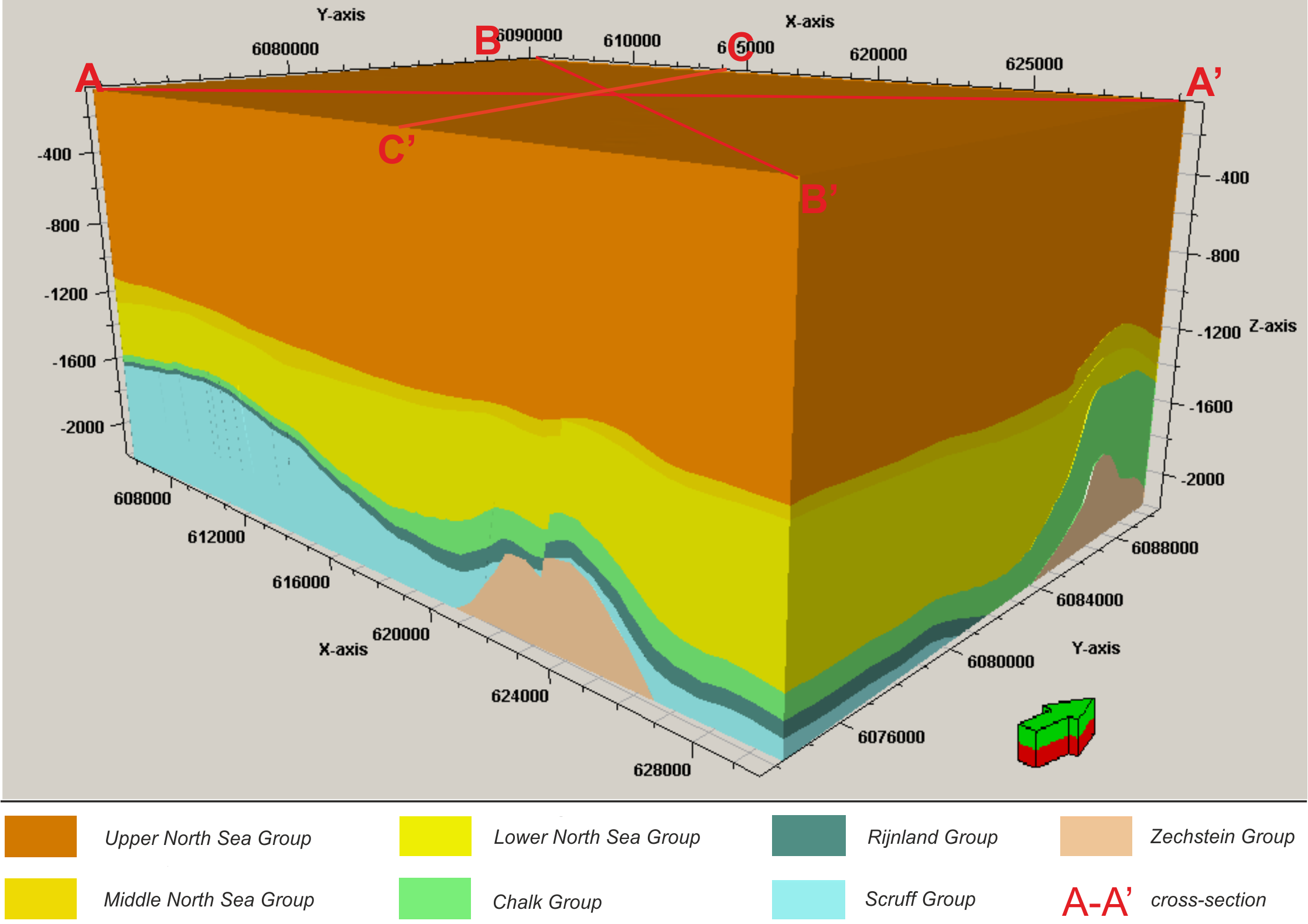
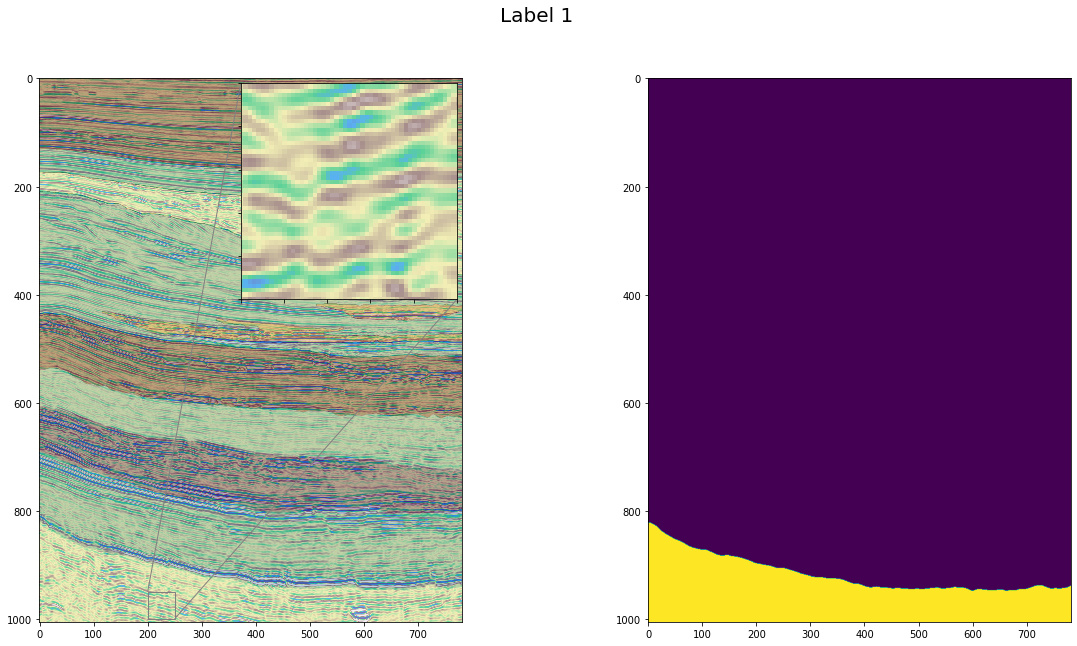
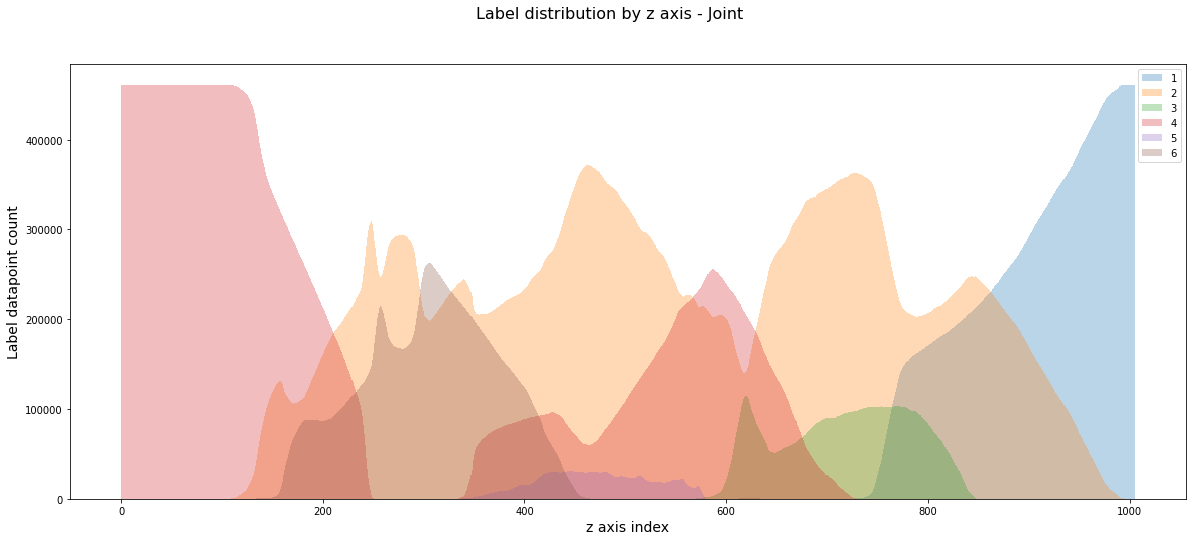
We can extract a ton of information just by looking at the cubes from various axes: it is an invaluable insight into the data itself. As my specialization is horizon detection, I tried to look at borders between facies and analyze them. As was already mentioned by other participants, facies picking is very subjective; yet, I was able to find interesting patterns of labeling that can be used for the improving models.
Overall, it is pretty much the same as in any other contest: check the distributions, create visualizations, get familiar with the data itself.
Placeholder for a link to an amazing COLAB notebook.
2. Segmentation model
The next notebook shows everything for submission creation:
- Data loading: generating data along both spatial axis
- Applying a few image-related augmentations
- NN architecture with all the training hyperparameters
- Validation on left-off data
- Sequential prediction on the test data and storing the prediction in the needed format
There are quite a few parameters that can be changed: from the architecture to the way we generate data during the training phase. There is also an ever-present question of whether to add seismic attributes to the model input or just hope that a huge neural network can figure our everything it needs on its own. All of these variables can have a huge impact on the outcomes and the scoring of the submission!
Placeholder for a link to an amazing COLAB notebook.
That is it for now! I will try to update every section with new insights and put everything to the COLAB as soon as possible. Feedback, suggestions and criticism is always welcome!
It is also worth mentioning, that we have a lot of articles and talks and conferences on the subject: right now, we are in the middle of running EAGE workshop on ML in Oil&Gas. If you are interested in any of this, be sure to contact us!
 Announcing Community Prize!
Announcing Community Prize! Prizes
Prizes
 The new deadline for submitting the explainers is 23th October, 2020, 12:00 UTC
The new deadline for submitting the explainers is 23th October, 2020, 12:00 UTC
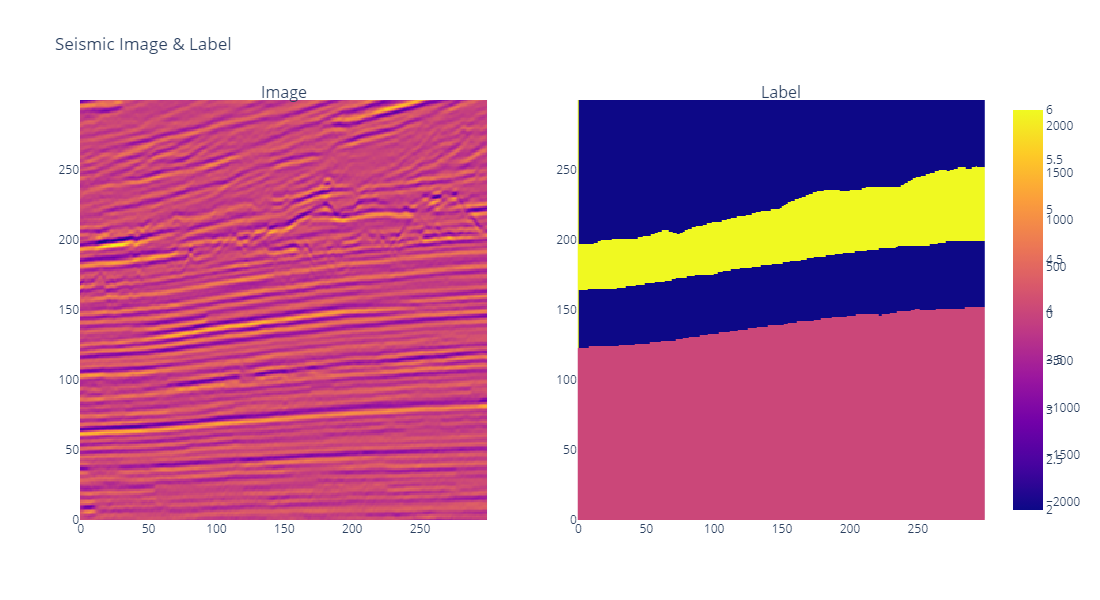
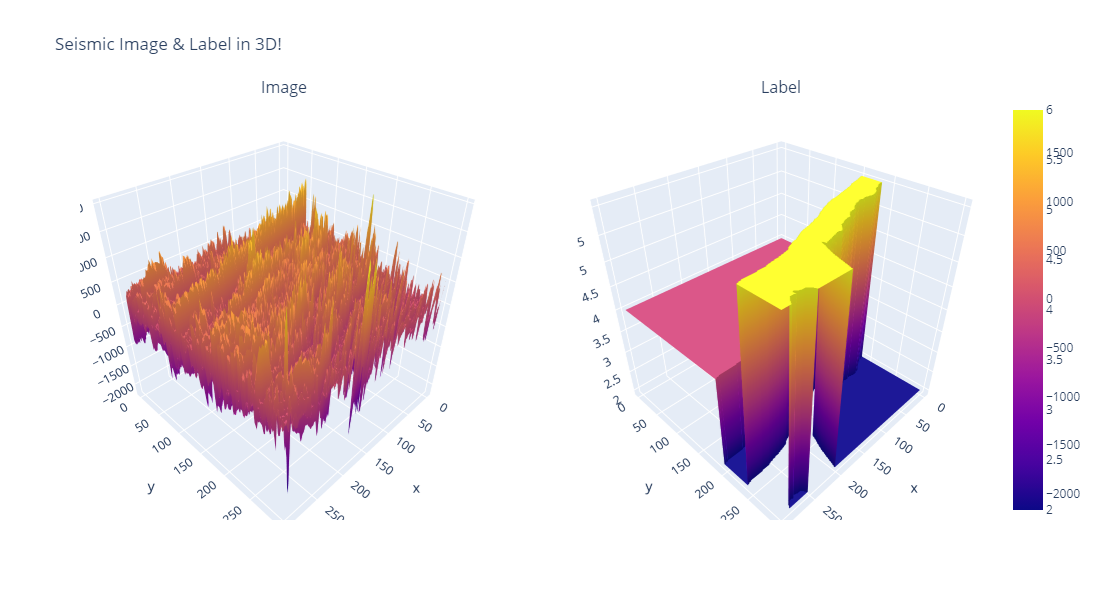









 . If the notebook did help you, make sure to like the post. lol.
. If the notebook did help you, make sure to like the post. lol.