How can we identify which images and ground truth data in the single-turn dataset are exclusively related to Task 1?
Thanks
How can we identify which images and ground truth data in the single-turn dataset are exclusively related to Task 1?
Thanks
Hi Seb,
Task 1 and task 2 use the same dataset (i.e. the single turn dataset). The only difference is the allowed search source.
Yes but how can we distinguish between task 1 and task 2 the samples? or the ground truth? which one is neccesary the search source?
I don’t quite understand your question. Could you please clarify?
Sure, sorry.
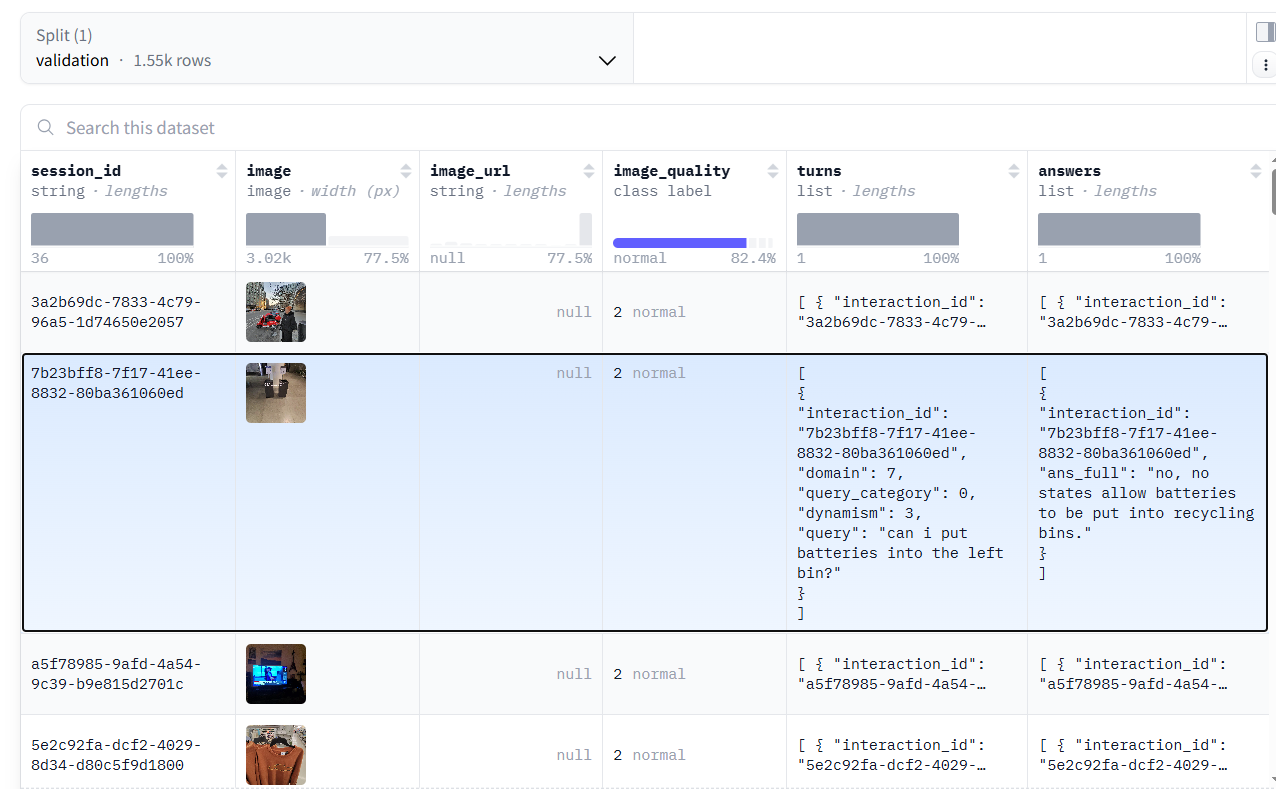
Out of the 1.55k images, which ones require a web search to correctly answer the ground truth, and which ones do not? The highlighted example with session_id: 7b23bff8-7f17-41ee-8832-80ba361060ed contains the following question:
“Can I put batteries into the left bin?”
And the corresponding ans_full is:
“No, no states allow batteries to be put into recycling bins.”
This example does not require a web search, because:
So even though an image is provided, the question and answer are not visually grounded and do not require up-to-date or external information.
How can we evaluate only images for task 1 :)?