The product_catalogue-v0.2.csv.zip for all the tasks has the following columns : product_id, product_title, product_description, product_bullet_point, product_brand, product_color_name, product_locale
Task 1
train-v0.2.csv.zip contains the following columns : query_id, query, query_locale, product_id, esci_label
test_public-v0.2.csv.zip contains the following columns : query_id, query, query_locale, product_id
sample_submission-v0.2.csv.zip contains the following columns : query_id, product_id
Task 2
train-v0.2.csv.zip contains the following columns : example_id, query, product_id, query_locale, esci_label
test_public-v0.2.csv.zip contains the following columns : example_id, query, product_id, query_locale
sample_submission-v0.2.csv.zip contains the following columns : example_id, esci_label
Task 3
train-v0.2.csv.zip contains the following columns : example_id, query, product_id, query_locale, substitute_label
test_public-v0.2.csv.zip contains the following columns : example_id, query, product_id, query_locale
sample_submission-v0.2.csv.zip contains the following columns : example_id, substitute_label
aicrowd datasets download -c esci-challenge-for-improving-product-search
# if you don't have AIcrowd CLI installed
pip install -U aicrowd-cli
Submissions
You can make the submissions by clicking on the Create Submission button on the challenge page. Please do remember to select the correct Task from the drop down before submitting.
The Create Submission button is only accessible after you accept the challenge rules by clicking on the Participate button.
We very much recommend making a first submission using the included sample_submission files for each of the tracks.
I struggle to download files. Looks like to be huge unzipped CSV files and when I click on download it does not download but open an Excel online view of the file, then I need to download.
Works for small files, but struggle with product_catalogue
# Using wildcard or file names, below will download all the Task 1's files
❯ aicrowd dataset download --challenge esci-challenge-for-improving-product-search "Task 1*"
# Using ID given in the table during listing
❯ aicrowd dataset download --challenge esci-challenge-for-improving-product-search 1
And obviously to install AIcrowd CLI , you can do:
❯ pip install -U aicrowd-cli
Welcome to KDD Cup and hoping for your submissions soon!
Hi @shuliang, the files are hosted on S3 so it is unlikely that there is issue on the server side.
Can you try changing your internet ISP in case it is throttling the download speed?
We will release compressed versions too soon for making it more accessible.
Please let all your feedbacks come in!
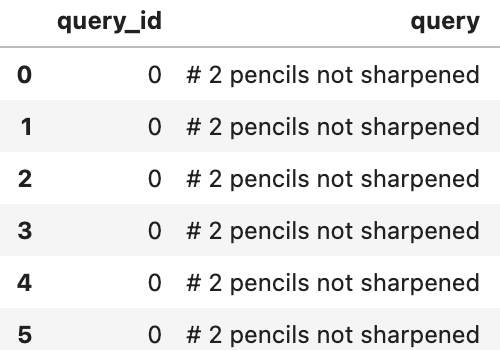
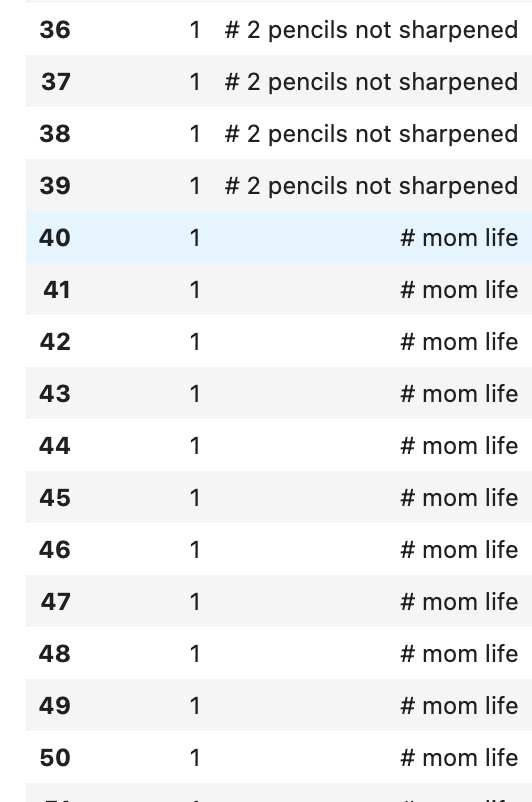
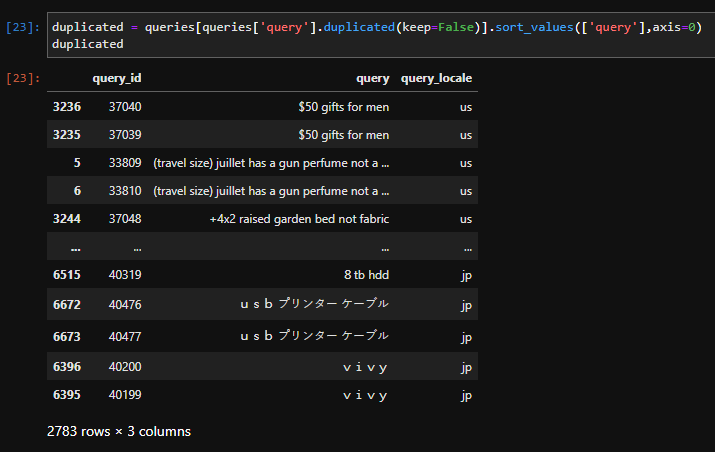
HI, @shivam for task-1, i see queryids are overlapping, is it expected? see attached screenshot for your reference!
Text of query_id=0 is overlapping in query_id=1 and so on
Hi @mohanty@shivam ,
I have some questions about the timeline and rules.
Entry Deadline: July 15, 2022 at 00:00:00 UTC. I’d like to know the exact meaning. Which is correct? Submit by July 14 at 23:59:59 or by July 15 at 23:59:59?
Can we use the other task’s dataset? E.g., make a model for task 1 by training with task 1-3 datasets.
Can we use some external data?
Can we use some public pre-trained model?
When admin or AIcrowd platform runs inference against the test dataset by using my submission (code and model), is there a limitation about computation time?
Hi! I want to make a code submission but it says ’ I am not authorized to access this page’ … you say i need to accept the challenge rules by clicking on the Participate button but i cant find it. Could you help me find it?

NOTE: This post has been updated to reflect the changes to the dataset. Please use





 , you can do:
, you can do: