@faroit
I recall in the presentation, when I showed the ragged time-frequency resolution of the sliCQT:
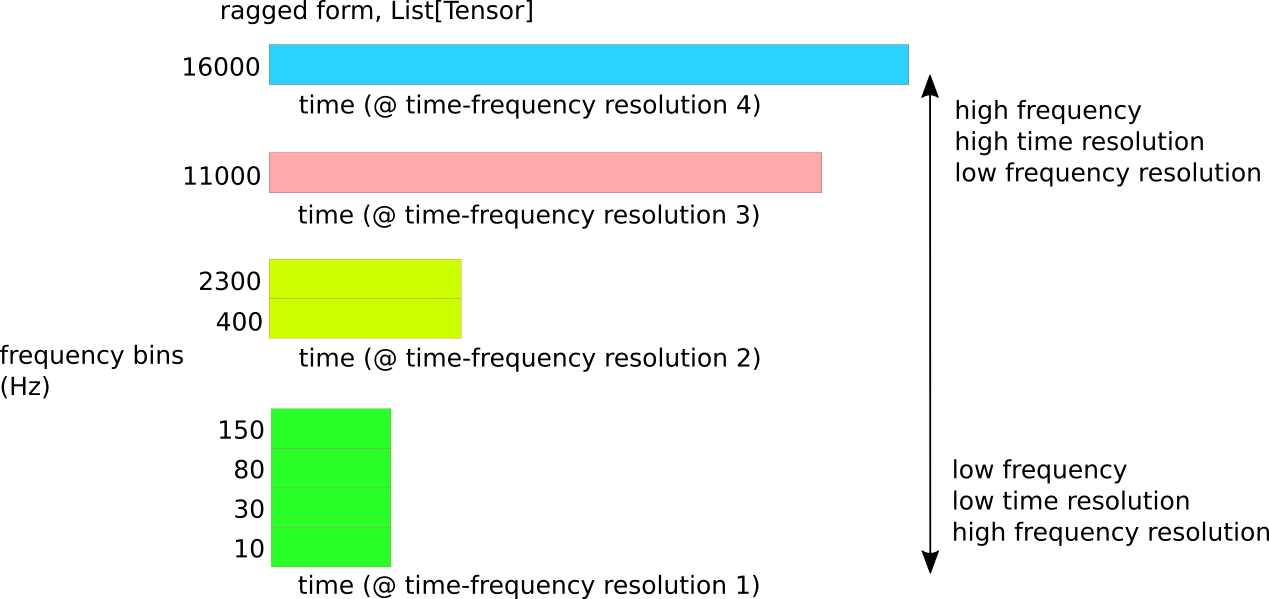
You asked if I tried interpolation.
The next evolution of the NSGT/sliCQT seems to be in this paper: https://www.researchgate.net/publication/274009051_A_Matlab_Toolbox_for_Efficient_Perfect_Reconstruction_Time-Frequency_Transforms_with_Log-Frequency_Resolution
Temporal alignment can be easily achieved by applying a common subsampling factor for all frequency bins k ∈1,…,K. That is, only the highest frequency channel is critically sampled and all other channels are subsampled with the same rate (we refer to this as full rasterization).
I believe rasterization is in the same vein as the interpolation you mentioned. I think implementing these Schörkhuber et al 2014 ideas into the NSGT library would give us the next evolution of a better sliCQT for music demixing.