Hi @vrv, can you please check the maximum submission/day, because in the rule it is 10 but we can’t submit more than 5 submissions.
1 Like
3 Likes
@vrv,
how are the submissions sorted on the Leaderboard? I think they are sorted only based on the log-loss score. But now(5/8 13:35 UTC) on the Leaderboard, it seems that #1 public log-loss score is 0.60837 and #2 is 0.60834. These submissions are tie if they are rounded on 3 decimal place, however, #2 was submitted earlier than #1. Is that an expected behavior of the Leaderboard?
in addition, do we need to select the final submission that is evaluated on the private leaderboard? or all submissions will be included on the private leaderboard?
i’m sorry if this is not appropriate place where we ask questions to competition admins.
1 Like
Hi @no_name_no_data,
As per the rules of the competition,
The Submission entry will be evaluated against the applicable ADDI Environment using multi-class log-loss, rounded to the third decimal place. The lowest logloss will be the best score. If two or more participating entries have the same log-loss score, the tie will be broken in favor of the Submission that was submitted first.
You do not need to select your final submission. All the submissions made are also evaluated on the private dataset. For the final leaderboard, the best score ( on 100% of the test set) among all your submissions will be considered.
Thanks for the clarification.
Just a side note to avoid any confusion:
Is the current public Leaderboard not reflecting the final methodology?
ie:

To the third decimal, @demarsylvain and I are equal, but mine was submitted a couple of hours before. 

If that was the final LB, I’d expect to be ranked prior?
1 Like
@ashivani,
Thank you for your reply.
It seems that the leaderboard has changed, but the order may still not be correct. (for example, there are 3 teams in rank#3, and the team that has the second highest score and submitted the earliest is placed at the bottom among them.)
Is it still being fixed?
Is it really ok to consider all submissions? if so, I think a solution that just happen to overfit the test dataset is more likely to be selected as the best.
1 Like
@ashivani, could you please precise the metric of the final leaderboard?
Will it be logloss as is (without any rounding) or it will be logloss rounded to the 3rd decimal (as we see at the Public Leaderboard)?
In my opinion it would be really unfair to rank the submissions by rounded logloss with the current level of competition (at the moment difference from top4 to top1 is about 0.001).
If, for example, one person gets final score 0.6065х he can lose to person with 0.6074х. It would be a “'little bit” frustrating.
2 Likes
change your username for “bordeleau_michael” … 

@ashivani
I agree with @konstantin_nikolayev. I think it is better to evaluate the submissions by more precise log loss score instead of rounded one.
In this competition, to improve the log loss by 0.000x (it may be ignored if rounded to the 3rd decimal) requires some effort.
if scores are rounded, it is more likely that the difference between better solution and others is just when it is created rather than what it is.
Though 0.000x improvement may not be so important for practical use, I think it is better to take the difference into consideration to make this competition fair.
1 Like
@ashivani, one more thing from me.
Could you please confirm that probing of LB and usage of true answers in submissions is prohibited and such submissions will be disqualified at the final leaderboard.
This question occured from this picture (look at screenshot below).
This behaviour of participant looks like situation I described above.
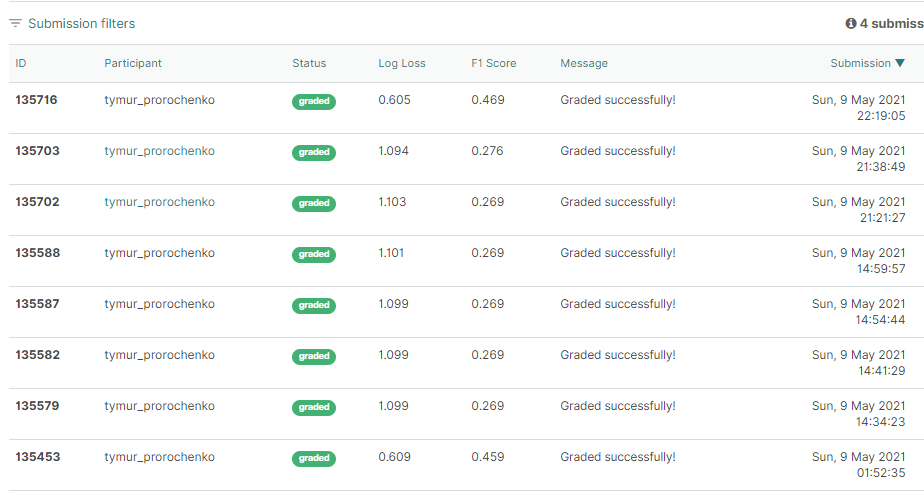
4 Likes
While in theory, you can probe the Leaderboard and seek the true answers, unless I’m missing something, this can’t replicate over the final leaderboard. 
i.e:
Let’s say I find out the true answers for record 1 to 25 on the Public Leaderboard. It boosts my public leaderboard position.
But, there’s no way for me to tell, on the final evaluation, which record is which in order to feed the correct answer. No?
Also, I’d be careful before calling out other participants like this. I think there are legitimate trial and errors that you can do. But if you are right, staff will notice by the structure of his code.
Anyways, just my opinion. 
Trust your work, and keep in mind overfitters will fail the final leaderboard. 
@michael_bordeleau Final test score will be computed on the complete test datasets, so if you prob in the pb lb then it will add little advantage.
Public test contributes 60% to final score - so the advantage could be sizable
1 Like
Hi all,
The leaderboard has been updated and reflect the condition in the rule. For the rounding of the precision to the 3rd decimal place, we are in touch with the ADDI team, and will post an update soon.
Note: The date mentioned in the leaderboard is of the last submission by the participant and not the submission which has the highest score.
Regards
Ayush
1 Like
@siddharth_singh8
I’m aware that the public lb is a subset of the final lb.
What I’m saying is that I don’t see any way to actually take advantage of it for your final score. You seem to think so… How would you apply it?
Perhaps I’m not seeing it… Methods I can think of would break on the final evaluation.
We are monitoring the situation on leaderboard and will take a decision on rounding of log-loss scores and tie-breaks very soon
3 Likes
@michael_bordeleau, what do you actually mean by final evaluation?
I guess, that there will not be rerun of submissions on the whole test because they are already run on whole test and now you see your score on 60% of test. As indirect proof of it (that submissions are run on whole test and not only on the part of it) look at my screenshot in the message above. Participant got the same as initial score 1.0986122886681096 twice after that. Why? Probably because he hit his probes into private rows two times (I’m definitely sure that it was probing).
So I don’t expect any rerun in the future and advantage of true answers (probing result) will remain at the Final LB. Anyway, just my opinion.
3 Likes
Ah! I understand you now!
I assumed our notebooks would be re-run on the final (complete) dataset.
You are saying that whenever we submit, our final score is also calculated behind the scene, but then we are shown a sub-score, based on 60% of the rows.
If that’s true… then yeah. I see the issue now. 
EDIT: also terrifying is that it hasn’t been addressed yet…
Can I submit constant predictions instead of ML model results? I think yes.
Can I submit different constant predictions for each row of the test dataset? I think yes. It not prohibited by rules.
Can I submit everything that I want in my 10 submissions per day? I think yes.
- Could you please clarify it?
- Could you please confirm that the final score will be calculated on 100% of the Test including this 60% that we can see on the leaderboard?
1 Like
Hi All,
Few contestants have raised the issue of leaderboard probing and ADDI wants make its stance clear on this issue. Here is the official comment:
“Per Section 10 of the Challenge Rules, ADDI has determined that leaderboard probing undermines the legitimate operation of the Contest and is considered an unfair practice. Therefore, any Entrants engaging in leaderboard probing will be disqualified, in accordance with the Challenge Rules and at ADDI’s sole discretion.”
5 Likes