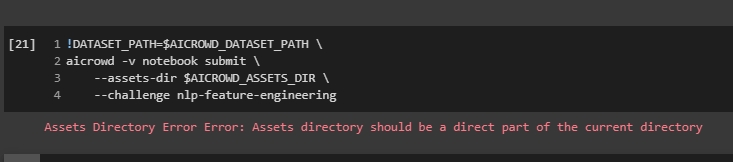
I have saved my model in assets directory, but i am still getting timeout error and local evaluatrion error
, here is the trace
Using notebook: /content/drive/MyDrive/Colab Notebooks/Copy of AI BLITZ 9 Community🤘.ipynb for submission...
Removing existing files from submission directory...
Scrubbing API keys from the notebook...
Collecting notebook...
Validating the submission...
Executing install.ipynb...
[NbConvertApp] Converting notebook /content/submission/install.ipynb to notebook
[NbConvertApp] Executing notebook with kernel: python3
[NbConvertApp] ERROR | unhandled iopub msg: colab_request
[NbConvertApp] ERROR | unhandled iopub msg: colab_request
[NbConvertApp] ERROR | unhandled iopub msg: colab_request
[NbConvertApp] ERROR | unhandled iopub msg: colab_request
[NbConvertApp] ERROR | unhandled iopub msg: colab_request
[NbConvertApp] ERROR | unhandled iopub msg: colab_request
[NbConvertApp] Writing 3113 bytes to /content/submission/install.nbconvert.ipynb
Executing predict.ipynb...
[NbConvertApp] Converting notebook /content/submission/predict.ipynb to notebook
[NbConvertApp] Executing notebook with kernel: python3
[NbConvertApp] ERROR | unhandled iopub msg: colab_request
[NbConvertApp] ERROR | unhandled iopub msg: colab_request
[NbConvertApp] ERROR | unhandled iopub msg: colab_request
2021-06-16 04:58:14.653518: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
[NbConvertApp] ERROR | Timeout waiting for execute reply (30s).
Traceback (most recent call last):
File "/usr/local/bin/jupyter-nbconvert", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python2.7/dist-packages/jupyter_core/application.py", line 267, in launch_instance
return super(JupyterApp, cls).launch_instance(argv=argv, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/traitlets/config/application.py", line 658, in launch_instance
app.start()
File "/usr/local/lib/python2.7/dist-packages/nbconvert/nbconvertapp.py", line 338, in start
self.convert_notebooks()
File "/usr/local/lib/python2.7/dist-packages/nbconvert/nbconvertapp.py", line 508, in convert_notebooks
self.convert_single_notebook(notebook_filename)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/nbconvertapp.py", line 479, in convert_single_notebook
output, resources = self.export_single_notebook(notebook_filename, resources, input_buffer=input_buffer)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/nbconvertapp.py", line 408, in export_single_notebook
output, resources = self.exporter.from_filename(notebook_filename, resources=resources)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/exporters/exporter.py", line 179, in from_filename
return self.from_file(f, resources=resources, **kw)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/exporters/exporter.py", line 197, in from_file
return self.from_notebook_node(nbformat.read(file_stream, as_version=4), resources=resources, **kw)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/exporters/notebook.py", line 32, in from_notebook_node
nb_copy, resources = super(NotebookExporter, self).from_notebook_node(nb, resources, **kw)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/exporters/exporter.py", line 139, in from_notebook_node
nb_copy, resources = self._preprocess(nb_copy, resources)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/exporters/exporter.py", line 316, in _preprocess
nbc, resc = preprocessor(nbc, resc)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/preprocessors/base.py", line 47, in __call__
return self.preprocess(nb, resources)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/preprocessors/execute.py", line 381, in preprocess
nb, resources = super(ExecutePreprocessor, self).preprocess(nb, resources)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/preprocessors/base.py", line 69, in preprocess
nb.cells[index], resources = self.preprocess_cell(cell, resources, index)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/preprocessors/execute.py", line 414, in preprocess_cell
reply, outputs = self.run_cell(cell, cell_index)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/preprocessors/execute.py", line 491, in run_cell
exec_reply = self._wait_for_reply(parent_msg_id, cell)
File "/usr/local/lib/python2.7/dist-packages/nbconvert/preprocessors/execute.py", line 483, in _wait_for_reply
raise TimeoutError("Cell execution timed out")
RuntimeError: Cell execution timed out
Local Evaluation Error Error: predict.ipynb failed to execute
 , and Prediction phase are the most important markdown. These should not be removed in any case.
, and Prediction phase are the most important markdown. These should not be removed in any case.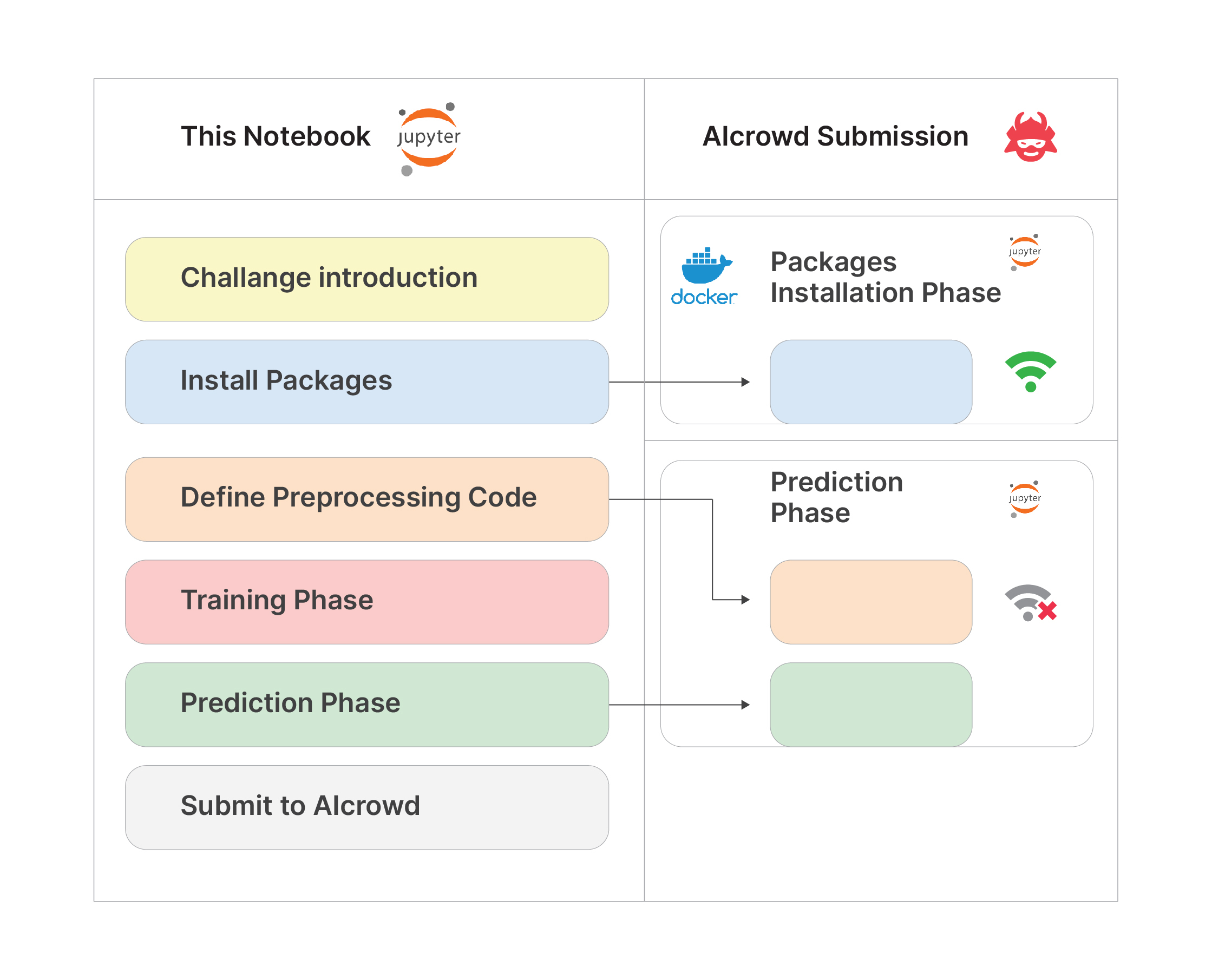
 markdown section.
markdown section.
 and AIcrowd Runtime Configuration as it is because after submitting your notebook, those environment variables will be used in many different cases.
and AIcrowd Runtime Configuration as it is because after submitting your notebook, those environment variables will be used in many different cases.
 . Also, I am trying to understand the problem statement-
. Also, I am trying to understand the problem statement-