I’m my training set the RMSE is a lot higher than on the leaderboard (out of sample). I’m wondering if it’s like that for others as well. Is there simply less extreme claims in the out of sample?
While we wait for others to respond, I just ran a very quick analysis to make sure nothing crazy is happening. The only main difference between the leaderboard data and the training data would be sample size.
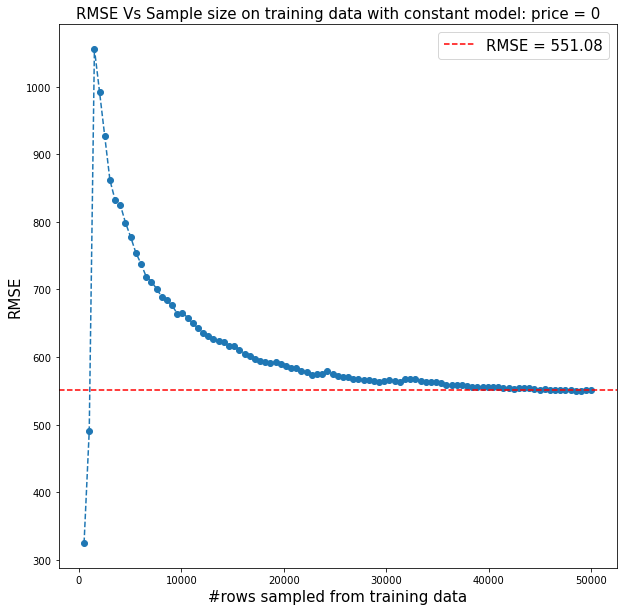
I created a constant model that prices every contract at zero. Then I increased the sample size from the training data to see how the RMSE behaves. You can see from the plot below that it converges to about 550 which is a little larger than what I would get on the RMSE leaderboard. But nothing that raises concern for me. I think you are right that it could be that the training data has a few very large claims that don’t appear in the RMSE leaderboard data, something that would be expected in a smaller dataset 
1 Like
Same here.
How do you treat those extrme claims?
For now I am using a cap, but I am also considering dropping those rows instead of it.
I see the same thing. It’s just because of the skewness of the loss data. If you set the seed to another number you’ll notice your RMSE change significantly across different potential validation sets.
2 Likes