During Christmas break I created this R starterpack to help people get started with submitting code for an xgboost.
I used a “tweedie” model, might be new for some folks. It allows you to model claim amount directly and is an alternative to using a frequency + a severity model
I also used the “recipes” package, which insure that you won’t create extra dummy variables by mistake.
I purposefully set the hyperparameters to something absolutely stupid. I also didnt do any clever feature engineering.
Then it got me my highest RMSE score. It was like 3rd position for RMSE back then, so I backed up on my original project of sharing it and forgot about it until today.
I removed my trained_model.xgb , so you will have to at least re-run fit_model and re-zip everything before submitting. I’d also consider implementing a better pricing strategy. It simply adds a 1$ markup
Anyway here it is: https://github.com/SimonCoulombe/aicrowd_insurancepricing_starterpack
I’m embarrassed to say that I just used up my submission limit today to try different seeds… and @simon_coulombe, you got really lucky with the seed . I guess 42 is the answer to everything.
I’m not surprised it was a lucky draw. I don’t use it, I just wanted to share how to make a submission using zip file and do a quick shout-out to the tweedie model. At the very least you’ll want to do some feature engineering, cap the outliers and find some decent hyperparameters.
Trust your CV, no need to submit to the leaderboard all the time
@michael_bordeleau , regarding the tweedie parameter and leakage. I’m not a thinker, but if it’s good enough for @arthur_charpentier4 then it’s good enough for me.
source: Computational Actuarial Science with R (Arthur Charpentier 2015)
I was at a point were it was clear I had leakage somewhere in my project. And that’s when I started doubting everything I had done.
Made a checklist and decided what could be material or not.
I tried using your xgboost parameters on my processed data with a lot of complex feature engineering, and it didn’t perform any better. I tried ensembling your xgboost with my other base models… and nothing is beating your original xgboost. Craziness…(I’m amusing myself with the RMSE leaderboard since at least it gives immediate feedback. I’m about out of ideas for the pricing strategy and none of what we tried worked well.)
A few years ago a member of my team, who is an actuary and Kaggle master, used to delight in tormenting the rest of us when his models out-performed ours on leaderboards.
He would always insist his out-performance was due to his process of selecting lucky seeds.
We all knew full well there’s no such thing, that generalises to the private leaderboard, but many a time I caught myself trying a few different seeds to see if I can get lucky and beat his model.
There is of course nothing wrong in running a few models with different seeds and taking the average result. That’s a recognised technique called bagging which will often improve a model at the cost of implementation complexity.
Its honestly not a very strong model. I’m pretty sure it was only doing fine until people caught up that they needed to increase their prices a bit.
I’ll probably adjust my profit margin for the last week, but I don’t think I’ll revisit the model too much. I’m very happy that I managed not to sink too much time on this competition and would rather keep it that way.
I have spent a lot of tiem THINKING about it, but it doesnt feel as bad

 I’m going to have to dig into this. Thanks so much!
I’m going to have to dig into this. Thanks so much!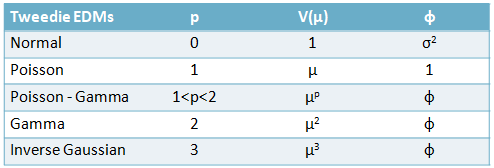
 . I guess 42 is the answer to everything.
. I guess 42 is the answer to everything.
