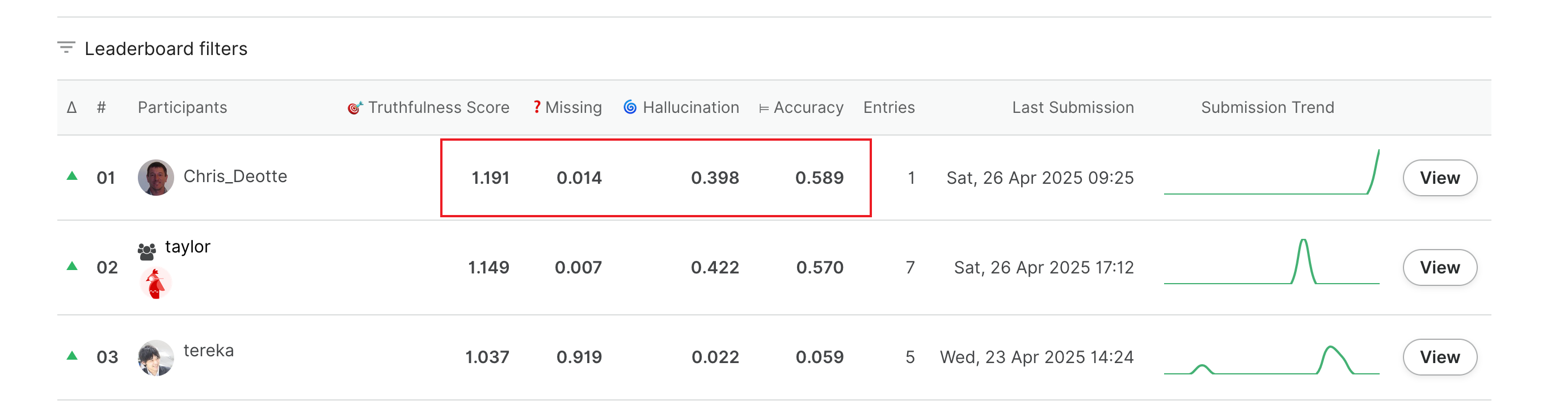
According to current leaderboard(take track-1 as example):
-
It seems that the leaderboard is sorted by accuracy instead of truthfulness, which is contradict with the document:
-
The calculation of the truthfulness seems not to be correct. Hallucination will cause negative score, and the truthfulness should be negative for baseline with a high hallucination. Using local_evaluation in the start kit will lead to a reasonable result below:
But I don’t know how the truthfulness in the leaderboard is calculated, which seems strange.
1 Like
+1 to your questions.
I have additional related questions to the organizer:
- Is the prompt defined in local_evaluation.py the one used for auto-evaluation of the leaderboard?
- If no, can you share the prompt used for the leaderboard?
- If yes, how does it define “acceptable” (score: 0.5)?
1 Like
For question 1, we are looking at it.
For question 2, it is reasonable as accuracy is +1, hallucination is -1, so the overall score should be accuracy - hallucination, which is indeed the case here (0.2623 - 0.6311 = -0.3688).
But in the leaderboard, it seems that the truthfullness score is not calculated as the same with local_evaluation.py. Take the score below as an example:
How to calculate 1.191 with the scores later?@yilun_jin8
This is a bug on the leaderboard. We have identified the cause of the bug and have rolled out a few fixes to solve the bug.
It takes some time, but soon all scores of previous submissions (with wrong scores) will be updated to the correct ones, and the new submissions will have the correct scores.
Thanks for improving the leaderboard. There are still 5 things wrong with the leaderboard. Can you please fix the following 5 things? Thanks.
-
Multi-source Augmentation (task 2) ranking is being determined by “Ego Samples” when ranking should be determined by “All Samples”. Furthermore, when we click to see mulit-source augmentation LB, we should see “All Samples” first by default.
-
Multi-source Augmentation (task 2) ranking is being sorted by “Accuracy” when ranking should be determined by “Truthfulness”.
-
Multi-turn QA (task 3) ranking is being determined by “Ego Samples” when ranking should be determined by “All Samples”. Furthermore, when we click to see mulit-turn QA LB, we should see “All Samples” first by default.
-
Mulit-turn QA (task3) “Ego Samples” is displaying all scores as NAN
-
Top score on Single Source Augmentation (task 1) incorrectly computes truthfullness as 0.889 when their hallucinations are 0.219 and accuracy is 0.108 (i.e. their truthfulness should be -0.111. Other team truthfulness scores were updated yesterday but this score was not updated).
Thanks for fixing these 5 issues!
1 Like
Hey @shizueyy!
Thanks a ton for flagging this!
Quick updates:
- The leaderboard sorting has been fixed! It’s now correctly based on
truthfulness, just as it should be.
- We also found a sneaky bug in the evaluator that was throwing off the truthfulness scores. We’ve re-evaluated all graded submissions with the right formula. The leaderboard should already reflect the updated scores — but if you spot anything odd, don’t hesitate to reach out to us!
Appreciate you keeping an eye out!
Hey @Chris_Deotte,
Huge thanks for taking the time to point these out — super valuable feedback, and we really appreciate it!
Here’s what we’ve fixed after your message:
- We updated the leaderboard ordering. Now for Multi-source Augmentation, the “All Samples” leaderboard is shown first, followed by “Ego Samples,” just like it should be.
- The leaderboard sorting is now based on
truthfulness instead of accuracy, as expected.
- For Multi-turn QA, the ordering has also been corrected — “All Samples” leaderboard shows up first now.
- Regarding the
NaN scores for “Ego Samples” in Multi-turn QA: it turns out the dataset shared by Meta doesn’t include any ego samples. We’re going to double-check with them just to be extra sure.
- About that missing re-evaluation: looks like a few sneaky submissions slipped past our re-evaluation queue. We just caught them and ran a fresh re-evaluation. The scores should now be fully updated on the leaderboard.
Thanks again for raising all these points so clearly. If you spot anything else, we’re all ears!
Note: The evaluation dataset has been updated and we will trigger another re-eval soon. So please expect all the scores to update.
We are still waiting to hear back from the organizing team from Meta, on some of the other open issues on the forum. That said, we are actively following up with them, while we try our best to resolve all the open issues in the ongoing challenge.
3 Likes