Now that everything is setup and working, I am having a hard time figuring out how to customize my inputs and change the config on the simulator, and the AICrowd wrappers and their documentation are a little confusing.
Things I cannot really find easily documented (trying to find it, but clarification would help):
- Why is the pose a 30 length vector? Why is it not just pitch, roll and yaw, and the 3 vector for the translation, giving the me 6 DOF representation of the 12 element pose transform matrix. I am talking about the pose as returned by the
env.step() function?
- The config file seems to suggest that I can access segmentation maps, and an overhead view, atleast during training. But the AICrowd wrapper’s
env.step() only gives me access to the 30-length pose vector, not the other stuff that seems useful. How do I get access to that? env.make() exists, which is called by the AICrowd evaluator class, should I just bypass the evaluator and instantiate my own simulator for training?
Small Error in documentation:
-
env.step() claims to return pose and image as a dict in the docstring, it even talks about the keys, even though it returns as a tuple as clearly mentioned in the docstring for env._observe().
2 Likes
Okay, so I got one part of it, the 30 length vector is described in the variables at top of the env.py file in the comments with the array. I am still confused as to what to pass to constructor of env to get the segmentation maps, and what are these something_if_kwargs variables that seem to be everywhere.
2 Likes
I tried a lot to get the segmentation map, it doesn’t work. There is a very clear type mismatch in RacingEnv.__init__ in the following lines, where self.cameras should have 3-tuples.
if birdseye_if_kwargs:
self.cameras.append(("CameraBirdsEye", utils.CameraInterface(**birdseye_if_kwargs)))
And the same with all others of the similar form. This cannot be ignored because later in the pipeline you do unpack this tuple as follows in the the multimodal setter.
for name, params, cam in self.cameras:
_shape = (params["Width"], params["Height"], 3)
_spaces[name] = Box(low=0, high=255, shape=_shape, dtype=np.uint8)
And unlike the self.cameras dict in the config, I don’t know what to set here. Some help please.
2 Likes
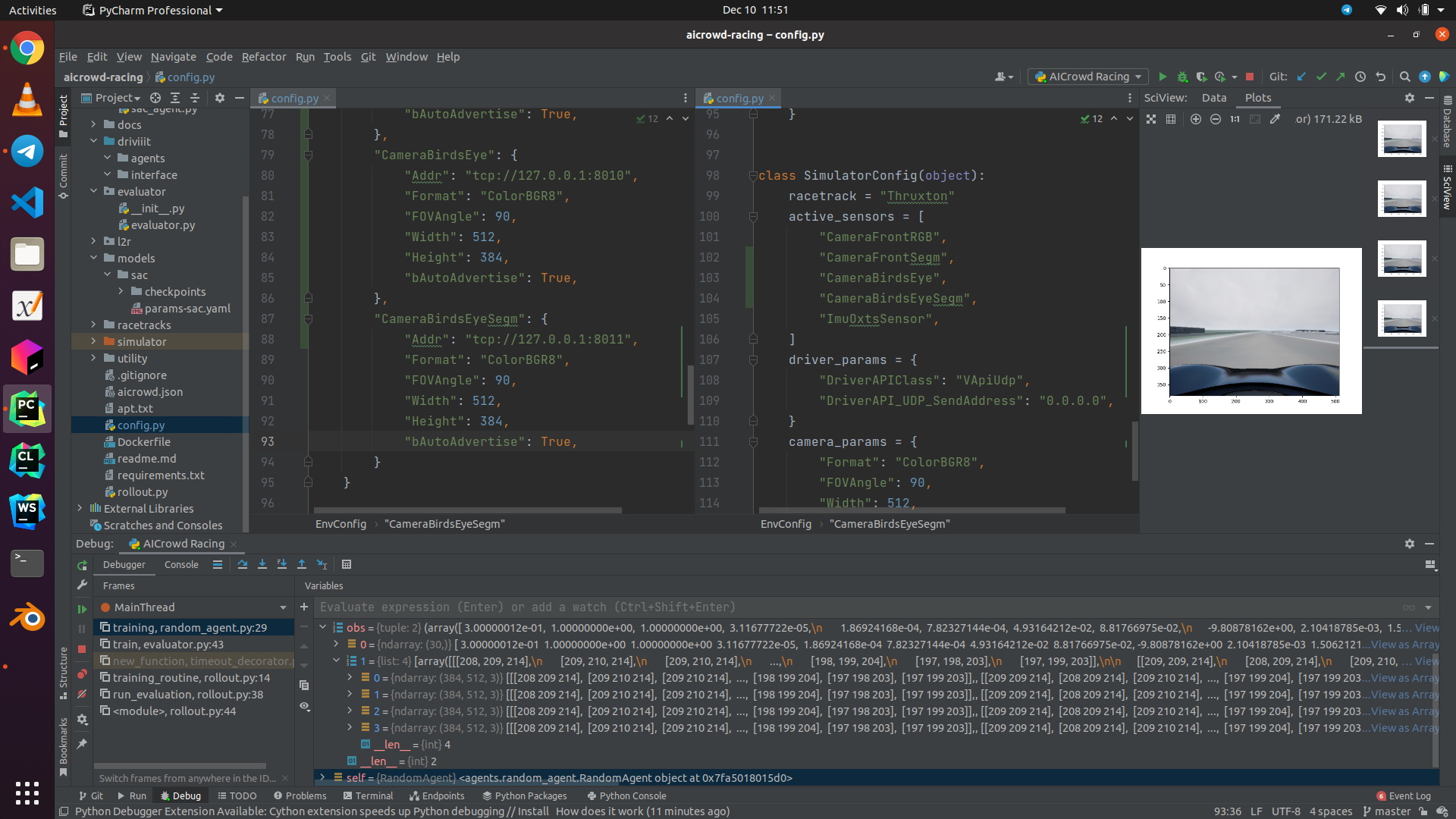
This picture tells it call, I changed the cameras config, I added the right sensors, I am getting 4 images, but WHY ARE THEY ALL THE SAME??? Where is my BirdsEye and Segmentation map? Are my settings as RGB8 and FOV 90 wrong? Are there more things I missed changing?
1 Like
Hello @AnimeshSinha1309,
I think I found a bug that is causing the problem with all images being the same.
In l2r-starter-kit/l2r/envs/utils.py, I changed lines 190-191 from
self.sock.connect(f"{ip}:{port}")
self.addr = f"{ip}:{port}" if not addr else addr
to
self.addr = f"{ip}:{port}" if not addr else addr
self.sock.connect(self.addr)
This resolves the issue since otherwise the socket connects to the default ip and port instead of the passed addr argument.
I hope this helps!
2 Likes
Thank you, thank you sooo much! That was the issue, I have spent so much time trying to debug it, I saw those lines but thought they were okay then. It works now, thanks a lot.