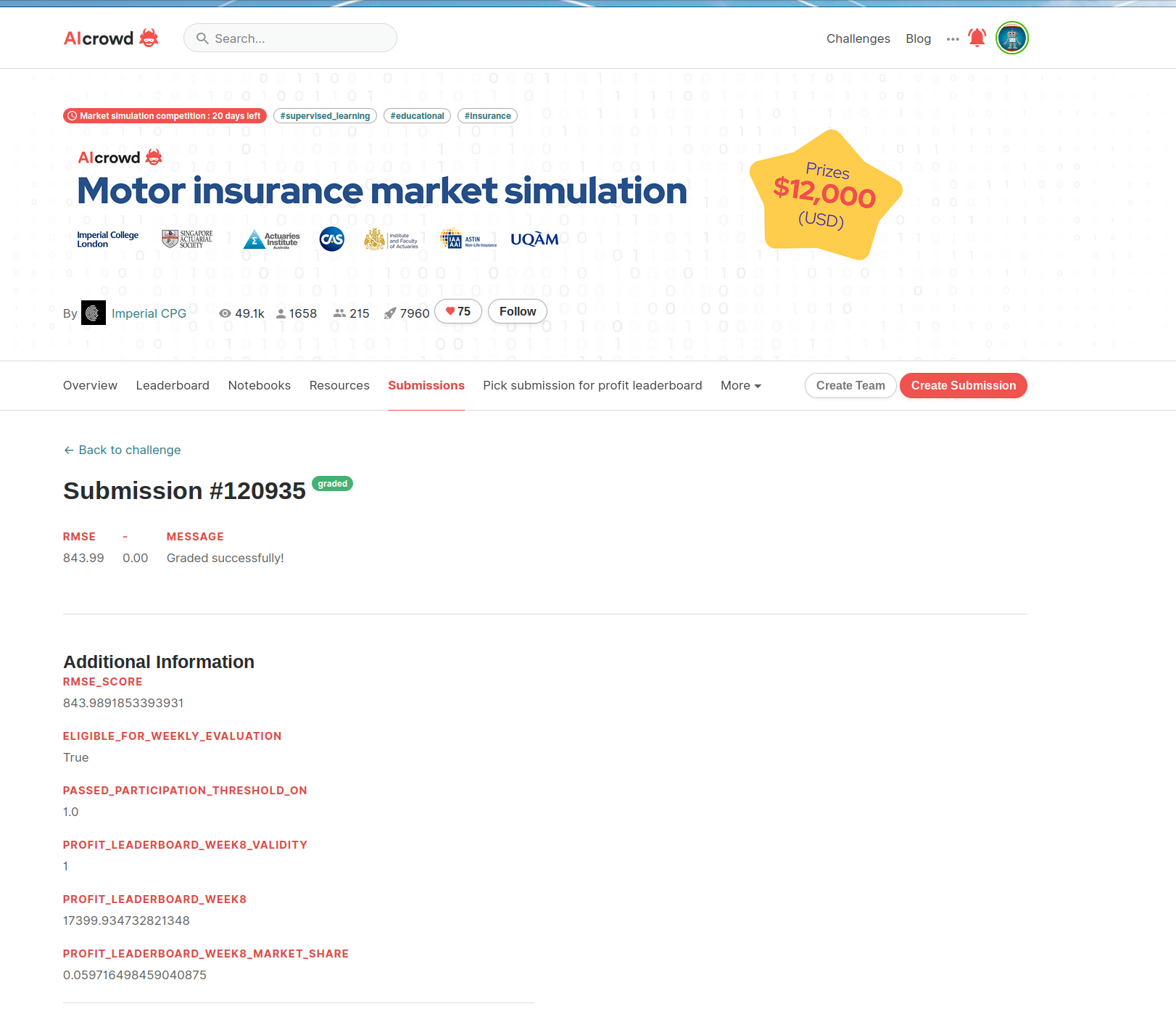
@theworst 's submission has an RMSE of 843 (!!) and managed to get the 5th place for profit.
3 Likes
but it is kinda funny…
Hi, guys. If my solution works until the end of the competition and you’re interested in knowing, I’ll explain it to you. I can say in advance that it is quite simple, and you can find the explanation.
3 Likes
sure! I’ll be interested even if it doesnt work 
My surprise is that you have a much larger RMSE than the model where the predicted claims is equal to the mean claim amount.
I’m guessing it’s because you want a very high price for everyone , but if that’s the case you could have set a high “predict_premium()” without fudging your “predict claims”.
cheers!
1 Like
My intuition is that the further up the leaderboard you look, the less correlated the RMSE score is with “model quality”, I.E. the ability of the model to generalise to new data. RMSE is more sensitive to the observations with large errors - in our case the rows with large claims - than many of the other model metrics that could have been chosen.
As an example, comparing these two dummy models using RMSE and MAE, the second model has more accurate predictions for 99.9% of the data and a better MAE, but worse predictions for the 0.1% of the data that has large claims and a worse RMSE.
.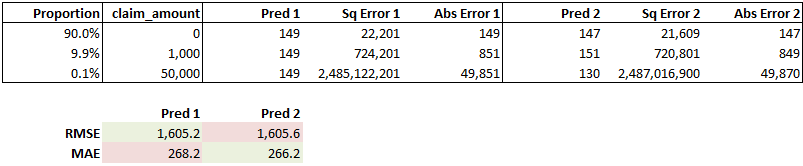
There is signal in how large claims are distributed of course, but they do tend to be quite random and noisy, so predicting the large claims in the leaderboard data well may not mean your model generalises well to other data sets.
For this reason, the signal to noise ratio in the RMSE metric is likely to decrease rapidly the higher up the leaderboard you look. It’s also noteworthy that the teams at the top of the RMSE leaderboard have more submissions than average suggesting random noise is significant.
And you may also have teams (like theworst?) that are building loads for profit into their claims predictions which will also lead to an uncoupling of the RMSE metric with the results from pricing.
4 Likes
I think you guys are also missing the point of the way this exercise has been set up. I assume all the people with RMSE<=500 are using XGboost, changing the hyperparameters each time and trying to outdo each other. In the real world, this is known as “hearding”. A better model in this case would be an accurate one that is as uncorrelated as possible with the other top ones - you would be identifying profitable segments that other entrants have not yet tapped.
2 Likes
Given the impact of a lucky seed on my starterpack, I can only agree that having a few hundred submissions will almost certainly make you climb the RMSE leaderboard without necesserily having a better model.
Regarding adding the profit margin to the predicted claims, that is almost certainly what happened given that his RMSE is much, much worse than the model that returns the same premium for everyone.
All I’m saying is that its funny that a model with a performance that appears to be much worse than returning the same price for everyone would have earned money to its creator last week.
1 Like
While that is true, all I’m saying is that its funny that a model with a performance that appears to be much worse than returning the same price for everyone would have earned money to its creator last week.
1 Like
Love it - we saw it as well! In our opinion, very likely @theworst included already the pricing adjustments into the fit_model{} function, instead of having one model for the expected loss and one for the prices … in fact, we wanted to do the same at one point, as it was easier to embed all the adjustments into one single model  but maybe we are wrong …
but maybe we are wrong …
1 Like