How we suppose to submit a model that agents are connecting to?
In the submission there is an agent implementation with OpenAI client that can access LLMs. Then, for tests I used local LLM server. But how I must submit it, and how it will be launched for evaluation?
You don’t need to submit your model directly for this challenge. When you make a submission, we automatically launch an instance of each game and provide your agent with a unique MCP address for that run. Each game reports its score back to us, and we update the leaderboard accordingly.
But how you will know which model to use? Either I would like to use llama, mistral, finetuned versions or just API (openai, claude,…)
You don’t need to submit the actual model for this challenge — only your agent implementation. During evaluation, AIcrowd automatically launches each game instance and provides your agent with a unique MCP server address to connect to.
As long as your agent can read the model endpoint from environment variables or config, you’re free to use a local Llama server, Mistral, OpenAI API, or even a custom-fine-tuned version hosted externally.
In our own industry (sportswear manufacturing), we follow a similar approach by connecting digital tools and AI-enabled features to remote services on Rajco USA.
So the flow remains very straightforward:
- Submit agent code

- Host your model wherever matches your use case
- AIcrowd interacts through MCP during evaluation
Hope this helps clarify how model selection and connectivity work for the challenge!
1 Like
So the model must be hosted externally and be accessible during evaluation?
I was also wondering how to submit my results and LLM.
-
If I don’t need to submit my model, how do you know the size of my model? (Track 1 requires less than 8B.)
-
Additionally, an important point is that my LLM server should be running on an external server to be evaluated by the contest host, right?
No, it doesn’t need to be hosted externally. We simply provide the endpoints that let you get game observations, and your agent only needs to return the actions to execute in the game. How you produce those actions whether through local models, external services, or any other setup is entirely up to you.
This means your machine must be able to access whichever models or services you rely on during inference.
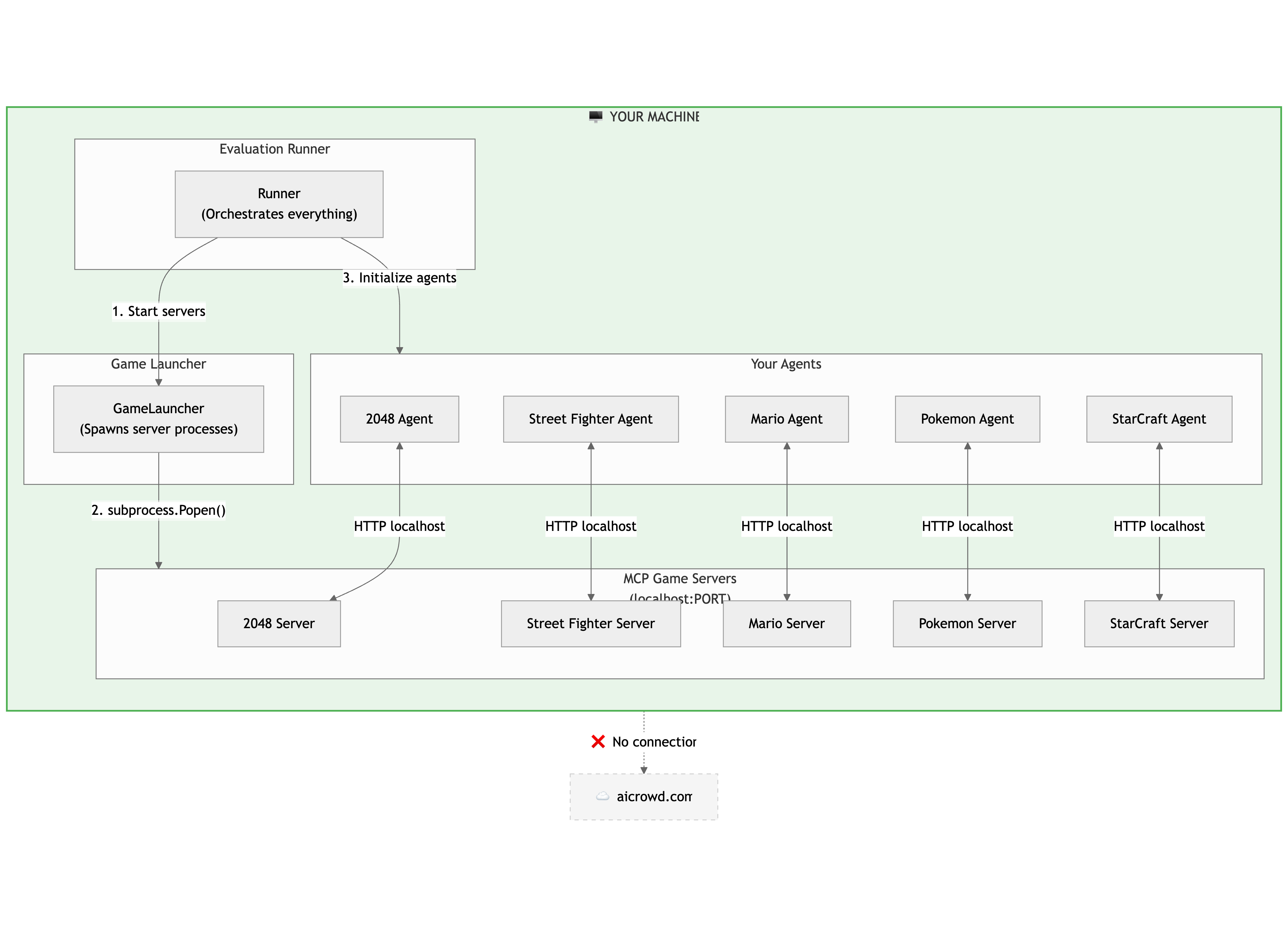
In Local Mode, everything (your runner, game launcher, agents, and the MCP game servers) runs directly on your machine. The runner starts the game servers, initializes your agents, and your agents communicate with the servers over localhost. There is no connection to the AIcrowd backend.
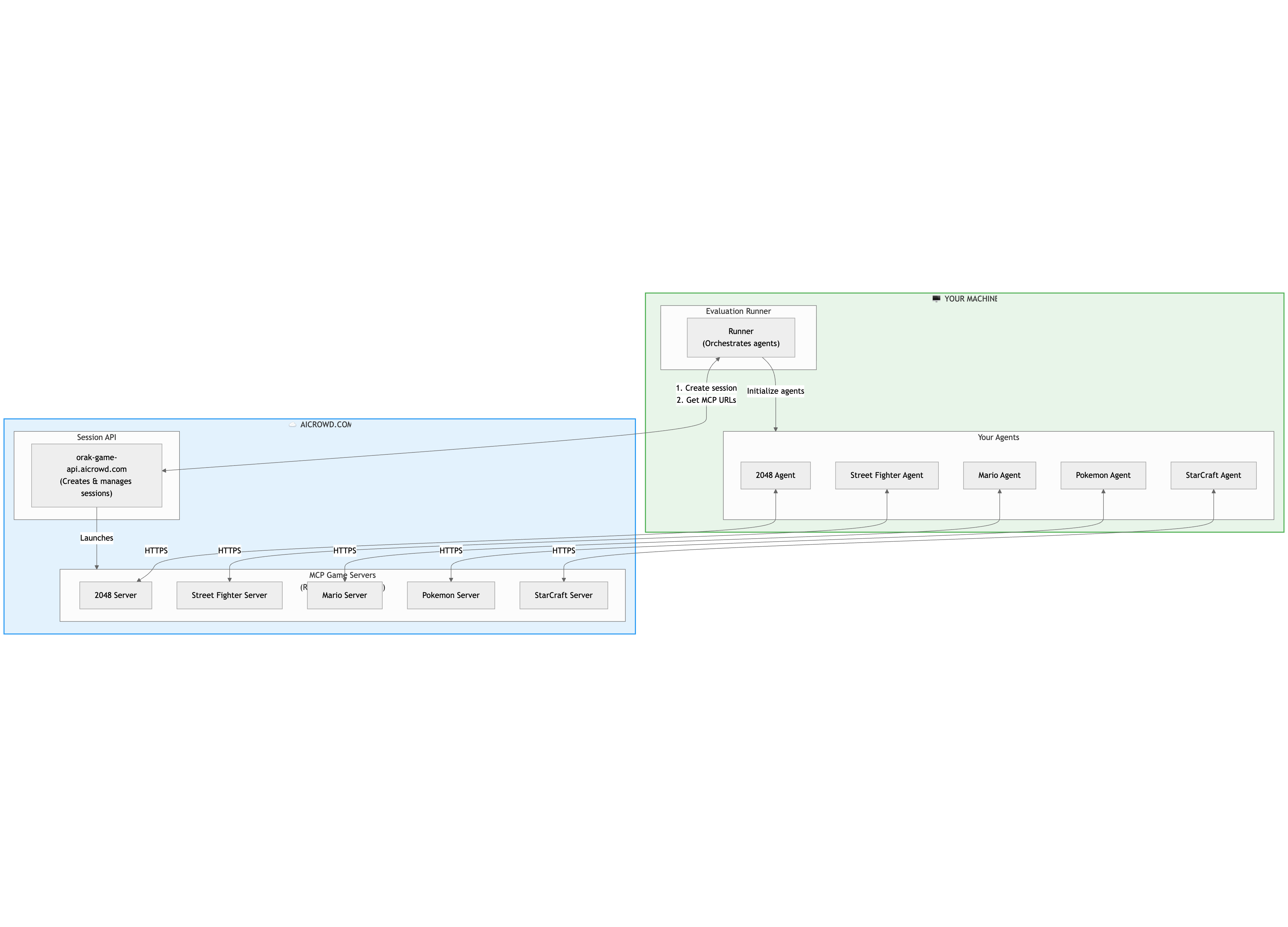
In Remote Mode, your runner and agents (including the LLM calls you make etc.,) still run locally, but the MCP game servers run on AIcrowd’s remote infrastructure. Your runner creates a session via the Session API, receives the MCP server URLs, and your agents interact with the remote servers over HTTPS.
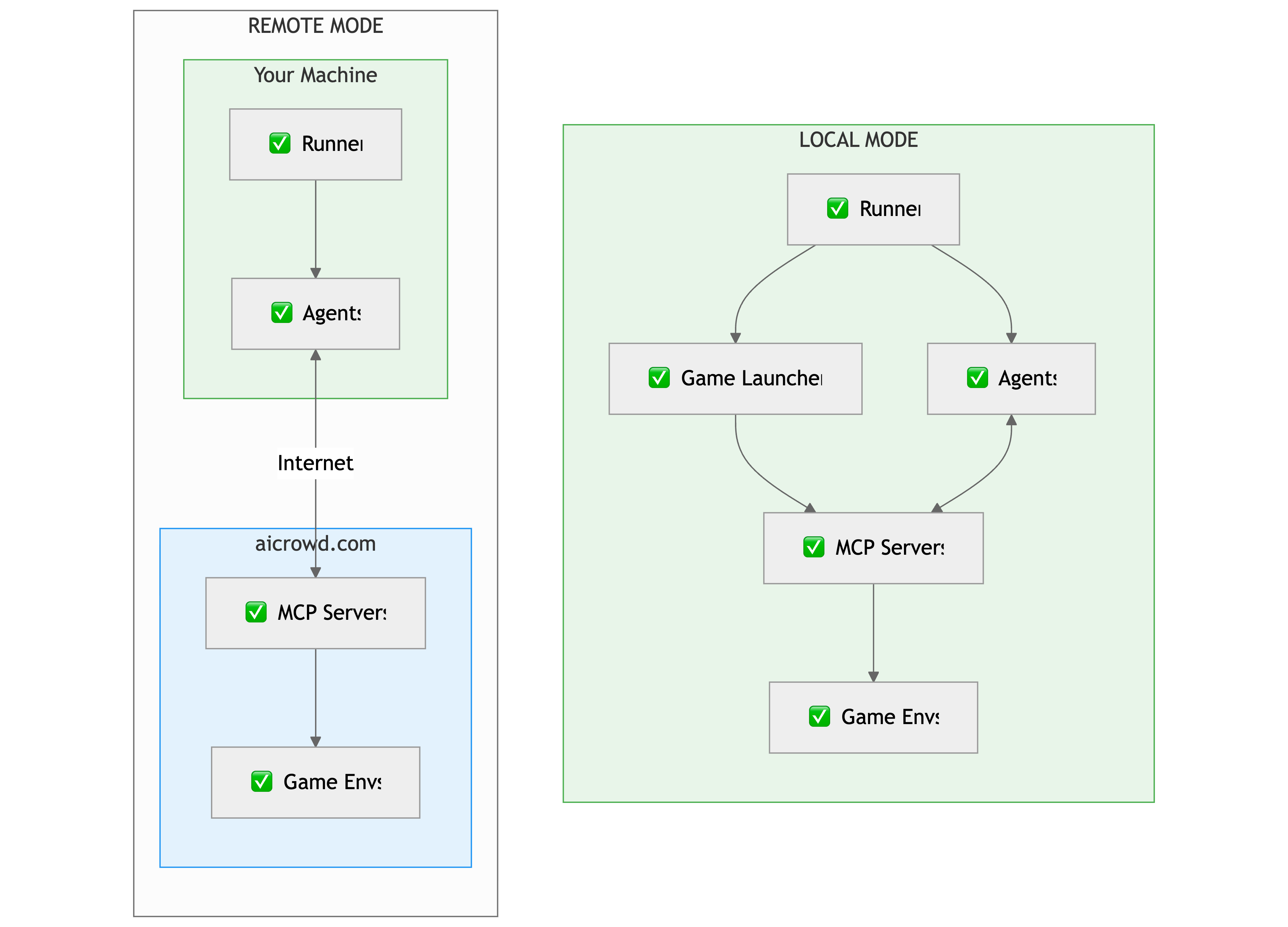
- Local Mode hosts the entire stack on your machine.
- Remote Mode keeps your agents local while offloading the game servers and environments to AIcrowd.
Hope this makes it clear
- The final evaluations would be manually run by Krafton AI team and the prizes would be decided based on the outcome of the manual runs. Krafton AI team would verify the size of the model you submit during the final evaluations.
- No, we do not require any sort of access to your LLM server. However, for the final evaluations, you would need to include precise instructions and code that is needed to start your LLM server and ensure that Krafton AI team is able to run everything end-to-end.
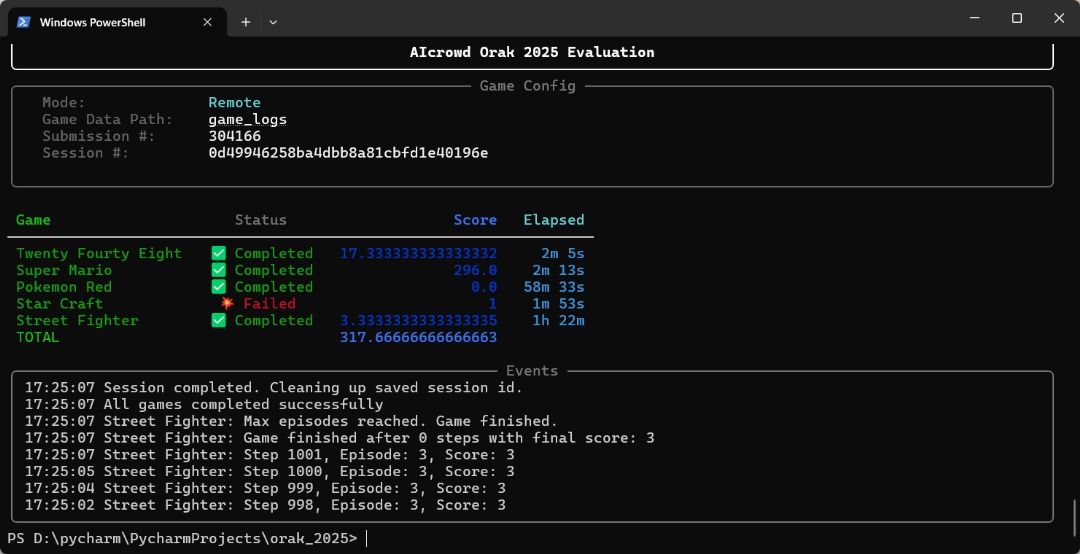
While running remote mode, it seems like the Star Craft failed after entering the second episode, is it possible that there’s a problem with the code in the MCP server or game envs of AIcrowd?
Also, may I know how long will the evaluation process usually take? Do score only appear after all games are completed? If so, will it directly show the score on the submission page once all games are completed or it will take some additional time to make the score shown on the submission page? If additional time is needed, how long it will usually be?
While running remote mode, it seems like the Star Craft failed after entering the second episode, is it possible that there’s a problem with the code in the MCP server or game envs of AIcrowd?
The issue was due to requests getting queued and dequeued arbitrarily at MCP server. We moved to a gRPC based implementation to get around this issue.
Please pull the recent changes made to starter kit and let us know if you still run into any issues.
long will the evaluation process usually take?
It’s subjective. However, if you use the random agents (not really random, they simply repeat the same static action), this is what you should expect.
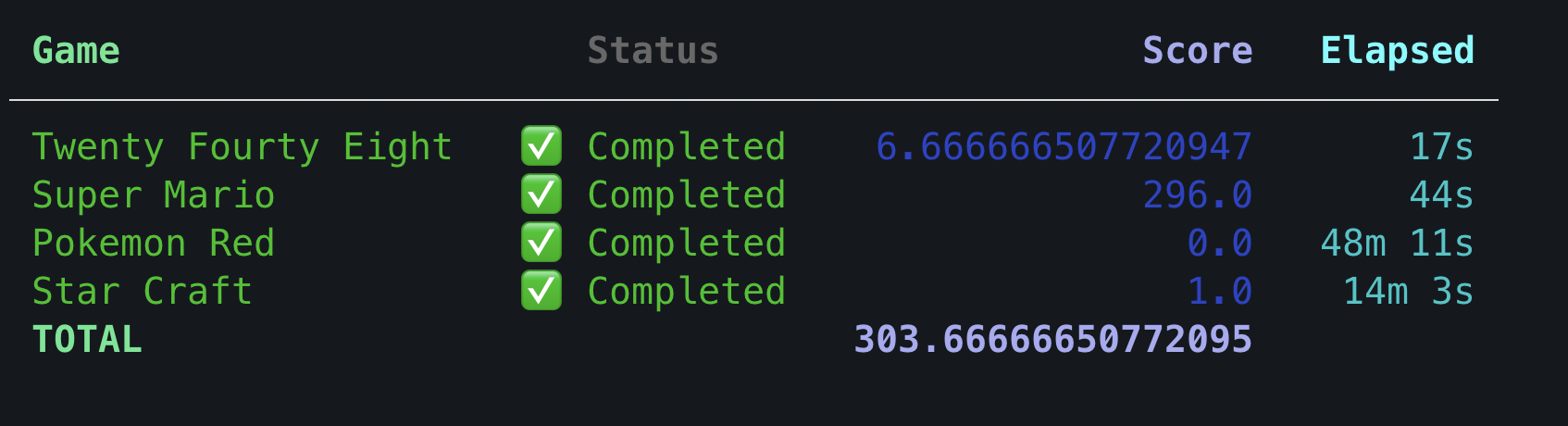
Do score only appear after all games are completed?
Yes. Your submission must complete all games to be marked as graded. Your submission won’t appear on leaderboard otherwise.
will it directly show the score on the submission page once all games are completed or it will take some additional time to make the score shown on the submission page
Your submission would be marked as failed if it doesn’t complete all the games. In case your evaluation times out i.e. doesn’t finish all the games in 12 hours, the submission would eventually get marked as failed.
I have a question regarding the eligible models for Track 1. According to the rules, the requirements are:
- Parameter limit: Max 8B total parameters.
- Release date: Pre-Nov 1, 2025.
- Fine-tuning: Allowed on public/team-created data.
Hypothetically speaking, would the following approach satisfy the conditions?
Taking a very simple model (e.g., a 1-layer model) that was released before November 1st, and fine-tuning it using Reinforcement Learning specifically for the “2048” game task.
My question is: Is it permissible to build and use such specialized models individually for each game task?
Thank you for your clarification.
2 Likes