Hi everyone,
We hope you are having fun playing with the dataset and preparing your submissions.
We noticed there are a few common mistakes/errors which can happen in your submissions.
Hopefully, this list will help you in avoiding them or capturing them early!
1. Multiple bbox for same track_id in single frame
2. Multiple object class for same track_id
Well, we know quantum computing is cool, and Schrödinger’s cat  is too.
is too.
Unfortunately, one object can’t have two bbox. Please make sure that you are submitting one bbox for each track_id.
Example:
This is wrong because track_id can’t have 2 bbox. 
| object | top | left | bottom | right | confidence | track_id |
|---|---|---|---|---|---|---|
| airplane | 1166.95416 | 1487.01367 | 1274.37005 | 1581.85522 | 0.3386299 | 3 |
| airplane | 974.525299 | 1310.66541 | 1397.71298 | 1414.01673 | 0.59356004 | 3 |
This is also wrong because the same track_id can’t be two different objects.
| object | top | left | bottom | right | confidence | track_id |
|---|---|---|---|---|---|---|
| airplane | 1166.95416 | 1487.01367 | 1274.37005 | 1581.85522 | 0.3386299 | 3 |
| airplane | 974.525299 | 1310.66541 | 1397.71298 | 1414.01673 | 0.59356004 | 0 |
| bird | 1167.36792 | 1492.7251 | 1247.83667 | 1573.73535 | 0.15650894 | 3 |
This is correct. 
| object | t | l | w | h | s | track_id |
|---|---|---|---|---|---|---|
| airplane | 1166.95416 | 1487.01367 | 1274.37005 | 1581.85522 | 0.3386299 | 3 |
| bird | 1167.36792 | 1492.7251 | 1247.83667 | 1573.73535 | 0.15650894 | 0 |
Although I hope bird is at a distance from airplane in above scenario 
3. TypeError: Object of type float32 is not JSON serializable
While registering the object using:
register_object_and_location(class_name, track_id, bbox, confidence, frame_image)
Please make sure that values like bbox, confidence, etc are JSON seralizable.
Example: np.float32 should be converted to float, etc.
This can be done easily in the evaluation codebase, but we don’t want to interfere with your predictions, and cause any unwanted transformation. 
4. bbox values
You need to submit the bbox during evaluation in [top, left, bottom, right] format in register_object_and_location function.
5. Hugh difference in online scores than local? 
We now report scores for your submission on two of the training flights i.e. e0d815053c1c46cfbd0b586b72718feb and ac23cb93c5c242d2b1bf0633fae9b1e6 in GitLab issue page. (both are present in part2 split)
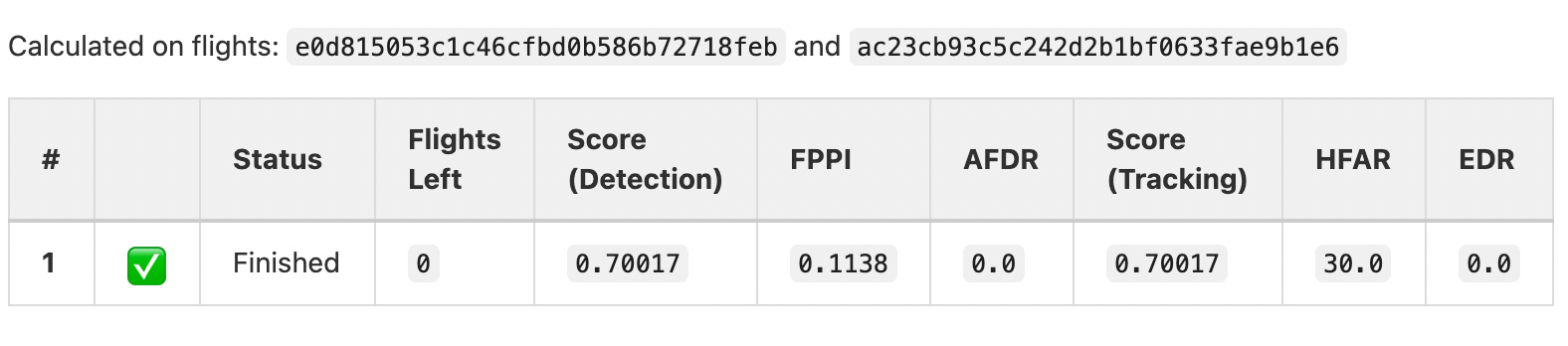
You can compare the scores with your local one generated using core/metrics/ for any potential score differences. This may help in detecting any interfacing mistake early on. Do let us know in case you continue facing different scores.
Example notebook is now available!
6. Tip  : You can remove
: You can remove Birds in your predictions
During the evaluation, we are not interested in alerting on birds – so you can remove birds from the results, to avoid unnecessary false positives.
7. Tip : Provide detections with only one class
Helicopter and Airplane can be renamed to “airborne” as we do not assess the correctness of classification. It may help in increasing FAR.
8. Tip : Dataset too big to play around with?
To experiment with fewer flights/images, you can also download a partial dataset (500G) using the partial=True flag in the Dataset class.
It includes all the frames with the valid encounters of the planned airborne objects. This can be a good start for your first training.
9. Reminder  : Timeouts
: Timeouts
The timeout for each flight is 600 seconds. (500ms/frame * 1200 frames/flight) 800 seconds.
10. Reminder : Office Hours and Help
We are hosting office hours every alternative week on Discord, please feel free to jump in case you want to discuss the challenge with the organizers and fellow participants.
Meanwhile, you can still post your queries 24x7 on Discord and Discussions Forum, and are highly encouraged to do so!
11. Reminder : Using SiamMOT Baseline?
Please note that identical SiamMOT models (with delta <= 1.5% in EDR or AFDR) will be disqualified from winning the prize. An identical model is a model that uses the exact same code and config file provided with the baseline.
12. Hardware used for evaluations?
We use p3.2xlarge to run your evaluations i.e. 8 vCPU, 61 GB RAM, V100 GPU.
(please enable GPU by putting "gpu": true in your aicrowd.json file)