Hi @zhichao_feng, your submissions have failed due to 90 minutes timeout for each public & private phase runs. (it got 92% in 90m)
Hi @vitor_amancio_jerony @qinpersevere & all,
The image building code has been updated on our side, and the repository size is no longer a restriction.
Please keep in mind that the resources available for inference are same for everyone i.e. Tesla V100-SXM2-16GB.
2 Likes
@shivam thanks, i saw my submission is init process for few hours, i can’t see any log for error,could you help me for check it?
here is submission:
AIcrowd Submission Received #193588 - 7
submission_hash : 3b8cea9ae65fb94418f0ec8b2a141b49971795c5.
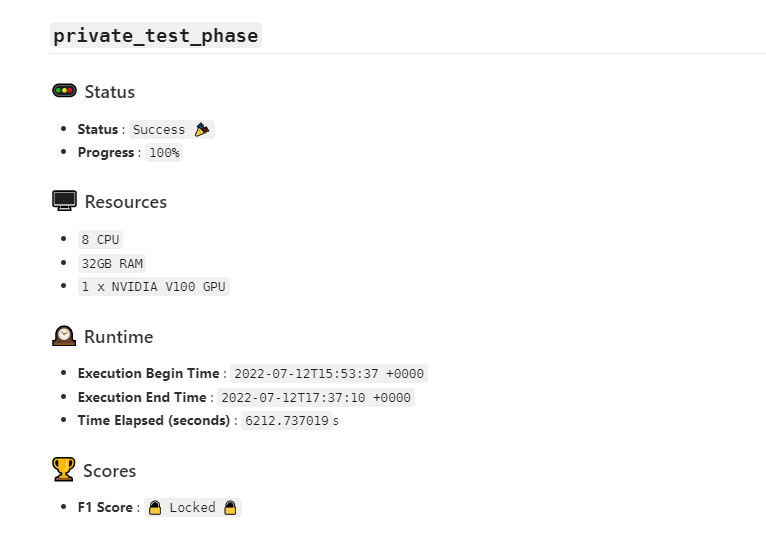
@shivam My submission took more than 90 minutes, but it was successful. Will it be counted as the final result? In addition, I found that the difference in submission time with the same amount of calculation will reach 2000 seconds. When two submissions are calculated at the same time, the calculation time will increase. Is there a GPU physically shared by multiple submissions when the same user submits a queue?
Hi @LYZD-fintech,
Each submission has dedicated compute resources.
The time elapsed, that is reported on the issue page is currently wrong and will be fixed soon, it shows the total time from the submission to completion (instead of start of execution of your code to the end). The timeout however is properly implemented and only considers the running time.
We provision a new machine dynamically for each submission, due to which the time elapsed might have been higher when there are a high number of submissions in the evaluation queue (multiple machines got provisioned)
I hope that clears any confusion.
Best,
Shivam
Thank you, but how do I know if my submission will be considered in the final ranking?
Hi @LYZD-fintech,
All the successful submissions would be considered for the final ranking in this challenge.
Best,
Shivam
Thanks, I have no problem. ![]()
@shivam @mohanty I’m getting CUDA out of memory error when loading my model on pytorch, even though run.py works on my own T4 and V100. I tested it inside the same container that the Dockerfile builds. I don’t know what else do to at this point.
Hash: af5e3e9d5a515b6917e2d39340da51e23b23d878
@mohanty @shivam
we meet the problem that the environment isn’t configured well for 2 hours
Could you take a look at it
submit hash: 00d6a5fb492d8648d5cc1724ce7efcd79b3f532d
@shivam
i have no idea for this case error log,can’t see any error,but failed
AIcrowd Submission Received #193832 - initial-15
submission_hash : 77fd92f1686f89bb2a0a4a09ab2cb83cce5f3e0c.
If this issue is not updated within a reasonable amount of time, please send email to help@aicrowd.com.
Could you also check my submission? I believe there is an unusual behavior of some hosting services. The code passed the public test set and soon failed for the private set. I also observed other participants’ submissions near the same time and all of them failed.
submission_hash : 540adaa2989b1c62dffc48659400db2cc0a13989.
@shivam
it‘s timeout for public test too?
have 2 process:
- data process spend 160s
��███▋ | 240263/277044 [02:38<00:26, 1370.87it/s] - predict spend 27m
[Predict] 2/271 […] - ETA: 27:15
i have no idea for timeout.
@wac81 : Yes, the timeouts apply to both the Public and Private Test Phases. Also, we have increased the timeout to 120 mins - please refer to this post : 📆 Deadline Extension to 20th July && ⏳ Increased Timeout of 120 mins
Best,
Mohanty
@wufanyou : The evaluation failed due to a timeout. The increased timeout of 120 minutes should fix this issue. We have re-queued your submission for re-evaluation.
Best,
Mohanty
Hi all, in case you feel your submission is running quite slow online v/s your local setup.
It might be a good idea to verify torch or relevant packages are installed properly.
Here is an example for torch:
In case you are confused how to verify for your package, please let us know and we can release relevant FAQs.
Hi @shivam and @mohanty. To debug this, I did the following: I’m printing nvidia-smi on my prediction_setup method, right before loading my model and it seems it gets executed 2 times, and that’s why I’m getting this CUDA out of memory error.
The first time it loads correctly but it can’t load a second time without releasing GPU’s RAM.
Any idea why it’s loading 2x?
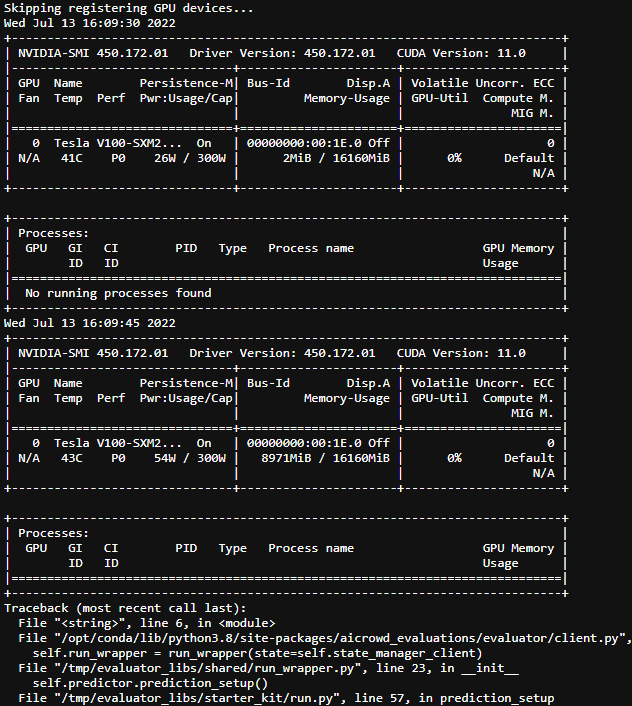
Hi @vitor_amancio_jerony, thanks for the logs.
We have identified the bug during the evaluation phase which caused the models to load twice, and is now fixed.
We have also restarted your latest submission and monitoring if any similar error happens to it.
1 Like