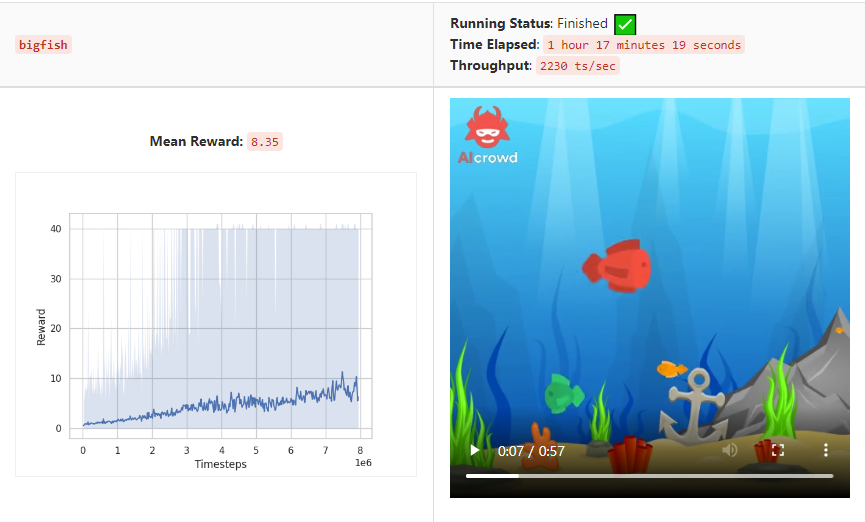
I don’t understand why max reward of env increase as my agents learn and learn.
Is max reward of env not random?
I don’t understand why max reward of env increase as my agents learn and learn.
Is max reward of env not random?
Hello @minbeom
The max reward that is returned during the training is not the max reward of the environment. For every iteration we collect mean, min and max reward values of the finished episodes during that iteration. For example if your single iteration has 4 episodes, the rewards array for your iteration is, say, [0, 6, 20, 10], then
mean_reward = 6
min_reward = 0
max_reward = 20
Please note that these min, mean and max rewards are for the episodes of an iteration. The graph you shared plots these values for every iteration.